Модели баз данных
Содержание:
- Как хранится информация в БД
- Принципы создания
- Иерархические
- Примеры реляционных СУБД
- Структурная таблица
- Системы управления базами данных
- Вас заинтересует / Intresting for you:
- Виды баз данных
- Мультимедиа данные
- Связь информационных систем и баз данных
- Иерархическая база данных, структура иерархических данных
- O(1) vs O(n2)
- В чём преимущества
- Локальный кэш распределенной информации
- Процесс проектирования
- Сетевые
- Проектирование реляционной базы данных. Преобразование модели в реляционную
- Динамичные базы данных
Как хранится информация в БД
В основе всей структуры хранения лежат три понятия:
- База данных;
- Таблица;
- Запись.
База данных
База данных — это высокоуровневное понятие, которое означает объединение совокупности данных, хранимых для выполнения одной цели.
Если мы делаем современный сайт, то все его данные будут храниться внутри одной базы данных. Для сайта онлайн-дневника наблюдений за погодой тоже понадобится создать отдельную базу данных.
Таблица
По отношению к базе данных таблица является вложенным объеком. То есть одна БД может содержать в себе множество таблиц.
Аналогией из реального мира может быть шкаф (база данных) внутри которого лежит множество коробок (таблиц).
Таблицы нужны для хранения данных одного типа, например, списка городов, пользователей сайта, или библиотечного каталога.
Таблицу можно представить как обычный лист в Excel-таблице, то есть совокупность строк и столбцов.
Наверняка каждый хоть раз имел дело с электронными таблицами (MS Excel).
Заполняя такую таблицу, пользователь определяет столбцы, у каждого из которых есть заголовок. В строках хранится информация.
В БД точно также: создавая новую таблицу, необходимо описать, из каких столбцов она состоит, и дать им имена.
Запись
Запись — это строка электронной таблицы.
Это неделимая сущность, которая хранится в таблице. Когда мы сохраняем данные веб-формы с сайта, то на самом деле добавляем новую запись в какую-то из таблиц базы данных. Запись состоит из полей (столбцов) и их значений. Но значения не могут быть какими угодно.
Определяя столбец, программист должен указать тип данных, который будет храниться в этом столбце: текстовый, числовой, логический, файловый и т.д. Это нужно для того, чтобы в будущем в базу не были записаны данные неверного типа.
Соберем всё вместе, чтобы понять, как будет выглядеть ведение дневника погоды при участии базы данных.
- Создадим для сайта новую БД и дадим ей название «weather_diary».
- Создадим в БД новую таблицу с именем «weather_log» и определим там следующие столбцы:
- Город (тип: текст);
- День (тип: дата);
- Температура (тип: число);
- Облачность (тип: число; от 0 (нет облачности) до 4 (полная облачность));
- Были ли осадки (тип: истина или ложь);
- Комментарий (тип: текст).
- При сохранении формы будем добавлять в таблицу weather_log новую запись, и заполнять в ней все поля информацией из полей формы.
Теперь можно быть уверенными, что наблюдения наших пользователей не пропадут, и к ним всегда можно будет получить доступ.
Реляционная база данных
Английское слово „relation“ можно перевести как связь, отношение.
А определение «реляционные базы данных» означает, что таблицы в этой БД могут вступать в отношения и находиться в связи между собой.
Что это за связи?
Например, одна таблица может ссылаться на другую таблицу. Это часто требуется, чтобы сократить объём и избежать дублирования информации.
В сценарии с дневником погоды пользователь вводит название своего города. Это название сохраняется вместе с погодными данными.
Но можно поступить иначе:
- Создать новую таблицу с именем „cities“.
- Все города в России известны, поэтому их все можно добавить в одну таблицу.
- Переделать форму, изменив поле ввода города с текстового на поле типа «select», чтобы пользователь не вписывал город, а выбирал его из списка.
- При сохранении погодной записи, в поле для города поставить ссылку на соответствующую запись из таблицы городов.
Так мы решим сразу две задачи:
- Сократим объём хранимой информации, так как погодные записи больше не будут содержать название города;
- Избежим дублирования: все пользователи будут выбирать один из заранее определённых городов, что исключит опечатки.
Связи между таблицами в БД бывают разных видов.
В примере выше использовалась связь типа «один-ко-многим», так как одному городу может соответствовать множество погодных записей, но не наоборот!
Бывают связи и других типов: «один-к-одному» и «многие-ко-многим», но они используются значительно реже.
Принципы создания
Каждая таблица, которую еще называют отношением в реляционной базе СУБД, содержит один или ряд категорий данных в столбцах атрибутах. Каждая строка называется записью, или кортежем, содержит уникальный экземпляр данных или ключ для категорий, установленных столбцами. Таблица имеет уникальный первичный ключ, идентифицирующий информацию в ней. Табличная связь устанавливается с помощью внешних ключей, ссылающихся на первичные ключи иной таблицы.
Например, типичная реляционная база СУБД бизнес-заказов имеет таблицу, в которой описывается клиент, со столбцами для имени, адреса, номера телефона и другой информации. Следующая имеет заказ: продукт, клиент, дата, цена продажи и так далее. Пользователь РБД получает представление о базе данных в соответствии со своими потребностями. Например, менеджеру филиала может понравиться просмотр или отчет обо всех клиентах, которые купили товары после определенной даты. Специалист по финансовым услугам в той же компании из тех же таблиц получает отчет о счетах, которые необходимо оплатить.
Иерархические
Иерархия — это когда есть вышестоящий, а есть его подчинённые, кто ниже. У них могут быть свои подчинённые и так далее. Мы уже касались такой модели, когда говорили про деревья и бустинг.
В такой базе данных сразу видно, к чему относятся записи, где они лежат и как до них добраться. Самый простой пример такой базы данных — хранение файлов и папок на компьютере:

Видно, что на диске C: есть много папок: Dropbox, eSupport, GDrive и все те, которые не поместились на экране.
Внутри папки GDrive есть ###_Inbox и #_Альбатрос, а внутри #_Альбатроса — десятки других папок. Если мы посмотрим на скриншот, то увидим, то должностная инструкция бухгалтера лежит с остальными файлами внутри папки Должностные и охрана труда, которая лежит внутри папки Инструкции.
Иерархическая база данных знает, кто кому подчиняется, и поэтому может быстро находить нужную информацию. Но такие базы можно организовать только в том случае, когда у вас есть чёткое разделение в данных, что главнее, а что ему подчиняется.
Примеры реляционных СУБД
SQLite — это популярная БД SQL с открытым исходным кодом. ПО может хранить всю БД в одном файле. Самым значительным преимуществом, которое она обеспечивает, является то, что все данные могут храниться локально без подключения к серверу. SQLite стала популярной для БД в мобильных телефонах, КПК, MP3-плеерах, телевизионных приставках и других электронных гаджетах.
MySQL — еще одна популярная реляционная модель СУБД SQL с открытым исходным кодом. Обычно она применяется в веб-приложениях и часто доступна с помощью PHP. Главные преимущества ее — простота использования, ценовая доступность, надежность. Некоторые из недостатков проявляются в том, что при масштабировании она страдает от низкой производительности, разработка с применением открытого исходного кода отстает с тех пор, как Oracle установил контроль над MySQL и не включает в себя некоторые расширенные функции.
PostgreSQL — это реляционная модель данных СУБД SQL с использованием открытого исходного кода, которая не контролируется какой-либо корпорацией. Обычно ее используют для разработки веб-приложений. PostgreSQL — простая, надежная и бюджетная программа с большим сообществом разработчиков. Имеет дополнительные функции в виде поддержки внешнего ключа, не требуя сложной настройки. Главный ее недостаток — она работает медленнее, чем иные БД, такие как MySQL. Она также менее популярна, чем MySQL, что затрудняет доступ хостов или поставщиков услуг, которые предлагают управляемые экземпляры PostgreSQL.
Структурная таблица
Таблица — это логическая структура, состоящая из строк и столбцов. Строки не имеют фиксированного порядка, поэтому, если извлекаются данные, может понадобиться отсортировать их. Порядок столбцов указывается при создании таблицы администратором БД. На пересечении каждого столбца и строки находится определенный элемент данных, называемый значением, или, точнее, атомарным значением. Таблица именуется высокоуровневым классификатором идентификатора пользователя владельца, за которым следует имя таблицы, например TEST.DEPT или PROD.DEPT.
Существует нескольких типов таблиц:
- Базовая, которая создается и содержит постоянные данные.
- Временная, в которой хранятся промежуточные результаты запроса.
Элементы таблиц:
- Столбцы имеют упорядоченный набор: DEPTNO, DEPTNAME, MGR и ADMK DEPT. Все они должны быть однотипными данными.
- Строки — каждая содержит данные для одного отдела.
- Значения на пересечении столбца и строки. Например, PLANNING — это значение столбца DEPT NAME в строке для отдела B01.
Индекс — это упорядоченный набор указателей на строки таблицы. В отличие от строк таблицы, которые не находятся в определенном порядке, индекс DB2 должен всегда поддерживать порядок.
Индекс используется для двух целей:
- Для повышения быстродействия получения значений данных.
- Для уникальности.
Создав индекс по имени сотрудника, можно получить данные для этого сотрудника быстрее, чем сканируя всю таблицу. Кроме того, создавая его, DB2 обеспечит уникальность каждого значения. Создание индекса автоматически создает индексное пространство, набор данных, который его содержит.
Системы управления базами данных
СУБД, как уже говорилось ранее, — это набор программ, делающих возможным построение баз данных и их использование. В обязанности СУБД входит:
Создание базы данных. Некоторые системы управляют одним большим файлом и создают одну или несколько баз данных внутри него, другие могут задействовать несколько файлов операционной системы или же непосредственно реализовывать низкоуровневый доступ к разделам диска. Пользователи и разработчики не должны заботиться о низкоуровневой структуре таких файлов, т. к. весь необходимый доступ обеспечивает СУБД.
Предоставление средств для выполнения запросов и обновлений. СУБД должна обеспечивать возможность запроса данных, удовлетворяющих некоторому критерию, например возможность выбора всех заказов, сделанных некоторым клиентом, но еще не доставленных. До того как SQL получил широкое распространение в качестве стандартного языка, способы выражения таких запросов менялись от системы к системе.
Многозадачность. Если с базой данных работают несколько приложений или к ней одновременно осуществляют доступ несколько пользователей, то СУБД должна гарантировать, что обработка запроса каждого пользователя не влияет на работу остальных. То есть пользователям приходится ждать, только если кто-то другой записывает данные именно тогда, когда им нужно прочитать (или записать) данные в какой-то элемент. Одновременно может происходить несколько считываний данных. На поверку оказывается, что разные базы данных поддерживают разные уровни многозадачности и что эти уровни даже могут быть настраиваемыми.
Ведение журнала. СУБД должна вести журнал всех изменений данных за некоторый период времени. Он может использоваться для отслеживания ошибок, а также (может быть, это даже важнее) для восстановления данных в случае сбоя системы, например внепланового выключения питания. Обычно производится резервное копирование данных и ведется журнал транзакций, т. к. резервная копия может быть полезна для восстановления базы данных в случае повреждения диска.
Обеспечение безопасности базы данных. СУБД должна обеспечивать контроль над доступом, чтобы только зарегистрированные пользователи могли манипулировать данными, хранящимися в базе, и самой структурой базы данных (атрибутами, таблицами и индексами). Обычно для каждой базы определяется иерархия пользователей, во главе этой структуры стоит «суперпользователь», который может изменять все что угодно, дальше идут пользователи, которые могут добавлять и удалять данные, а в самом низу находятся те, кто имеет право только на чтение. СУБД должна иметь средства, позволяющие добавлять и удалять пользователей, а также указывать, к каким возможностям базы данных они могут получить доступ.
Поддержание ссылочной целостности. Многие СУБД имеют свойства, способствующие поддержанию ссылочной целостности, то есть корректности данных. Обычно, если запрос или обновление нарушает правила реляционной модели, СУБД выдает сообщение об ошибке.
Вас заинтересует / Intresting for you:
База данных как объект правово… 535 просмотров Денис Wed, 27 Mar 2019, 03:16:24
Перенос корпоративных баз данн… 837 просмотров Дэн Fri, 27 Sep 2019, 07:52:18
Что такое SQL? Плюсы и минусы … 3586 просмотров Андрей Васенин Tue, 21 Nov 2017, 13:17:28
База данных и СУБД: основные п… 8169 просмотров Дэйзи ак-Макарова Fri, 24 Nov 2017, 05:30:03
Author: Светлана
Другие статьи автора:
Виды баз данных
Существует огромное количество разновидностей баз данных, отличающихся по различным критериям. Например, в «Энциклопедии технологий баз данных», по материалам которой написан данный раздел, определяются свыше 50 видов БД.
Основные классификации приведены ниже.
Классификация по модели данных
Примеры:
- Иерархическая
- Объектная и объектно-ориентированная
- Объектно-реляционная
- Реляционная
- Сетевая
- Функциональная.
Классификация по среде постоянного хранения
- Во вторичной памяти, или традиционная (англ. conventional database): средой постоянного хранения является периферийная энергонезависимая память (вторичная память) — как правило жёсткий диск.В оперативную память СУБД помещает лишь кэш и данные для текущей обработки.
- В оперативной памяти (англ. in-memory database, memory-resident database, main memory database): все данные на стадии исполнения находятся в оперативной памяти.
- В третичной памяти (англ. tertiary database): средой постоянного хранения является отсоединяемое от сервера устройство массового хранения (третичная память), как правило на основе магнитных лент или оптических дисков.Во вторичной памяти сервера хранится лишь каталог данных третичной памяти, файловый кэш и данные для текущей обработки; загрузка же самих данных требует специальной процедуры.
Примеры:
- Географическая
- Историческая
- Научная
- Мультимедийная
- Клиентская.
Классификация по степени распределённости
- Централизованная, или сосредоточенная (англ. centralized database): БД, полностью поддерживаемая на одном компьютере.
-
Распределённая БД (англ. distributed database) — составные части которой размещаются в различных узлах компьютерной сети в соответствии с каким-либо критерием.
- Неоднородная (англ. heterogeneous distributed database): фрагменты распределённой БД в разных узлах сети поддерживаются средствами более одной СУБД.
- Однородная (англ. homogeneous distributed database): фрагменты распределённой БД в разных узлах сети поддерживаются средствами одной и той же СУБД.
- Фрагментированная, или секционированная (англ. partitioned database): методом распределения данных является фрагментирование (партиционирование, секционирование), вертикальное или горизонтальное.
- Тиражированная (англ. replicated database): методом распределения данных является тиражирование (репликация).
Другие виды БД
- Пространственная (англ. spatial database): БД, в которой поддерживаются пространственные свойства сущностей предметной области. Такие БД широко используются в геоинформационных системах.
- Временная, или темпоральная (англ. temporal database): БД, в которой поддерживается какой-либо аспект времени, не считая времени, определяемого пользователем.
- Пространственно-временная (англ. spatial-temporal database) БД: БД, в которой одновременно поддерживается одно или более измерений в аспектах как пространства, так и времени.
- Циклическая (англ. round-robin database): БД, объём хранимых данных которой не меняется со временем, поскольку в процессе сохранения новых данных они заменяют более старые данные. Одни и те же ячейки для данных используются циклически.
Мультимедиа данные
Определение 1
Под мультимедиа-данными понимаются текстовые, графические, звуковые данные, данные с эффектами анимации, видеоданные и т.д.
Реляционные системы могут только хранить мультимедиа-данные, а создавать и редактировать такие данные способны только специализированные программы.
В реляционных системах для хранения данных предназначены таблицы. Для возможности хранения мультимедиа-данных в таблицах предусматриваются соответствующие поля. Также мультимедиа-данные могут быть сохранены в отчетах и экранных формах.
Главным отличием названных способов является связь мультимедиа-данных с каждой записью базы в первом случае и включение их в отчет или экранную форму один раз – во втором.
Мультимедиа-данные включаются в отчеты и экранные формы с целью повышения их наглядности при отображении на экране.

Различные СУБД содержат разные механизмы поддержки мультимедиа-данных. Зачастую для их размещения и хранения используют BLOB-поля (Binary Large OBject – большие двоичные объекты). Т.к. мультимедиа-данные могут быть различных видов (графические, аудио-, видео- и т.д.), а каждый вид может иметь разные форматы (например, графическая информация хранится в файлах с расширениями gif, tif, bmp и др.), удобно привязывать их к средствам обработки с помощью механизма OLE.
Поэтому наиболее распространенным типом BLOB-полей являются поля OLE.
Пример 1
Например, MS Access поддерживает поле объекта OLE, система Paradox позволяет создавать кроме того поля типа binary и graphic.
Для решения прикладных задач, в которых используются различные виды информации и преобладает символьно-числовая информация удобно использовать реляционную систему, которая содержит достаточно развитые средства поддержки мультимедиа-данных.
Связь информационных систем и баз данных
Определение 1
Логически связанные данные, формализованные каким-либо единым способом, таким образом, чтобы их можно было обрабатывать компьютером, называются базой данных
Базы данных создаются, хранятся и обрабатываются в специальных программах, называемых системами управления базами данных (СУБД).
Но для эффективной работы с данными одной лишь базы данных под управлением СУБД не достаточно. Обычно данные нужны для использования в каком-либо виде деятельности. Например, личные данные пациента нужны в процессе регистрации его медицинской карты в клинике, данные о проданных товарах нужны для ведения учета на предприятиях розничной торговли, данные о результатах сессии нужны в процессе начисления студентам стипендии и т.д. Все эти виды деятельности специфичны, в них есть свои правила и своя терминология. Поэтому для их информационной поддержки нужны специальные программы, где используется привычная терминология, а все правила учтены. Такие программы называются информационными системами (ИС).
Определение 2
Информационной системой называется аппаратно-программный комплекс, обеспечивающий накапливание, хранение и обработку данных с целью поддержки информационных процессов какого-либо вида деятельности.
Определение 3
Часть реального мира, которая подлежит изучению с целью разработки информационной системы, называется предметной областью.
Предметная область описывается множеством объектов, множеством процессов, использующих эти объекты, множеством пользователей, объединенных единым взглядом на всю систему.
Определение 4
Совокупность правил и принципов поведения объектов предметной области называют бизнес-логикой ИС.
Пример 1
Допустим, каждый покупатель магазина при наличии трех покупок, сделанных в течении месяца, получает скидку 2%. Это требование является частью бизнес-логики. При разработке ИС магазина оно должно быть учтено в виде отдельной процедуры, которая автоматически найдет таких покупателей и назначит им скидку.
При проектировании ИС необходимо определить, какие данные, и для каких целей будут храниться в системе, а также, каким образом будет организовано их хранение и обработка. Таким образом, база данных и СУБД являются составной частью (ИС). Кроме баз данных ИС включает в себя систему связанных друг с другом приложений, которые реализуют бизнес-логику.

Иерархическая база данных, структура иерархических данных
Когда речь идёт о хранении иерархических данных, каждый объект хранит информацию в виде определенной сущности, и у каждой сущности могут быть родительские и дочерние элементы, а у дочерних, в свою очередь, тоже могут быть дочерние элементы. Таким образом, можно сказать, что это данные, которые подлежат строгой иерархии (представьте себе своеобразное дерево).
Простой пример иерархических данных — документ в формате XML либо файловая система компьютера.
Нельзя не упомянуть и то, что базы данных этого вида оптимизированы под чтение информации. При такой структуре данные можно быстро выбирать из нужной области, отдавая запрашиваемую информацию пользователям. Например, компьютер легко работает с конкретной папкой либо файлом, которые, по сути, можно назвать объектами структуры иерархических данных. Но когда нужно перебрать всю информацию, это может занять время (если вернуться к вышеописанному примеру, то проверка антивирусом всех уголков нашего компьютера выполняется не так быстро, как хотелось бы).

На рисунке представлена классическая структура иерархической базы данных. Вверху находится родитель (его ещё называют корневым элементом), ниже размещены дочерние элементы. Элементы с данными, находящиеся на одном уровне, можно назвать братьями либо соседними элементами. БД данной категории бывают с разным количеством уровней и разной степени вложенности.
O(1) vs O(n2)
В настоящее время многие разработчики не заботятся о временной сложности алгоритмов … и они правы!
Но когда вы имеете дело с большим количеством данных (я не говорю о тысячах) или если вы боретесь за миллисекунды, становится критически важным понять эту концепцию. И как вы понимаете, базы данных должны иметь дело с обеими ситуациями! Я не заставлю вас потратить больше времени, чем необходимо чтобы ухватить суть. Это поможет нам позже понять концепцию оптимизации на основе затрат (cost based optimization).
Концепция
Временная сложность алгоритма используется, чтобы увидеть сколько времени займет выполнение алгоритма для данного объема данных. Чтобы описать эту сложность, используют математические обозначения больших О. Эта нотация используется с функцией, которая описывает, сколько операций нужно алгоритму для заданного количества входных данных.
Например, когда я говорю «этот алгоритм имеет сложность O (some_function() )», это означает, что для обработки определенного объема данных алгоритму требуется some_function(a_certain_amount_of_data) операций.
При этом важно не количество данных**, а то, ** как увеличивается количество операций при увеличении объема данных. Сложность по времени не дает точное количество операций, но хороший способ для оценки времени выполнения
На этом графике вы можете увидеть зависимость числа операций от объема входных данных для различных типов временных сложностей алгоритмов. Я использовал логарифмическую шкалу, чтобы отобразить их. Другими словами, количество данных быстро увеличивается с 1 до 1 млрд. Мы можем увидеть, что:
- O(1) или постоянная сложность остаются постоянными (иначе это не будет называться постоянной сложностью).
- O(log(n)) остается низкой даже с миллиардами данных.
- Наихудшая сложность — O(n2), где количество операций быстро растет.
- Две другие сложности так же быстро увеличиваются.
Примеры
При небольшом количестве данных разница между O(1) и O(n2) незначительна. Например, предположим, что у вас есть алгоритм, который должен обрабатывать 2000 элементов.
- Алгоритм O (1) обойдется вам в 1 операцию
- Алгоритм O (log (n)) обойдется вам в 7 операций
- Алгоритм O (n) обойдется вам в 2 000 операций
- Алгоритм O (n * log (n)) обойдется вам в 14 000 операций
- Алгоритм O (n2) обойдется вам в 4 000 000 операций
Как я уже сказал, по-прежнему важно знать эту концепцию при работе с огромным количеством данных. Если на этот раз алгоритм должен обработать 1 000 000 элементов (что не так уж много для базы данных):
- Алгоритм O (1) обойдется вам в 1 операцию
- Алгоритм O (log (n)) обойдется вам в 14 операций
- Алгоритм O (n) обойдется вам в 1 000 000 операций
- Алгоритм O (n * log (n)) обойдется вам в 14 000 000 операций
- Алгоритм O (n2) обойдется вам в 1 000 000 000 000 операций
Я не делал расчетов, но я бы сказал, что с помощью алгоритма O (n2) у вас есть время выпить кофе (даже два!). Если вы добавите еще 0 к объему данных, у вас будет время, чтобы вздремнуть.
Идем глубже
Для справки:
- Поиск в хорошей хеш-таблице находит элемент за O (1).
- Поиск в хорошо сбалансированном дереве дает результат за O (log (n)).
- Поиск в массиве дает результат за O (n).
- Лучшие алгоритмы сортировки имеют сложность O (n * log (n)).
- Плохой алгоритм сортировки имеет сложность O (n2).
Примечание: в следующих частях мы увидим эти алгоритмы и структуры данных.
Есть несколько типов временной сложности алгоритма:
- сценарий среднего случая
- лучший вариант развития событий
- и худший сценарий
Временная сложность часто является наихудшим сценарием.
Я говорил только о временной сложности алгоритма, но сложность также применима для:
- потребления памяти алгоритмом
- потребления дискового ввода / вывода алгоритмом
Конечно, есть сложности хуже, чем n2, например:
- n4: это ужасно! Некоторые из упомянутых алгоритмов имеют такую сложность.
- 3n: это еще хуже! Один из алгоритмов, которые мы увидим в середине этой статьи, имеет эту сложность (и он действительно используется во многих базах данных).
- факториал n: вы никогда не получите свои результаты даже с небольшим количеством данных.
- nn: если вы столкнетесь с этой сложностью, вы должны спросить себя, действительно ли это ваша сфера деятельности …
В чём преимущества
Базы данных и их системы управления заточены на работу с большим объёмом данных и от лица большого числа пользователей. Сейчас вы поймёте.
Скорость — ещё одно преимущество базы данных. База данных устроена так, что она легко и быстро находит, записывает, переписывает и снова находит данные. Всё потому, что СУБД всегда знает, что где лежит и по какому критерию искать. Там не будет случайных данных в случайном месте.
Скорость важна ещё и потому, что СУБД обычно обслуживает сразу много потоков: одновременно ей могут пользоваться десятки и сотни тысяч человек, поэтому ей некогда копаться. В хорошо сделанных БД всё молниеносно.
Сложность. Базы данных нужны в числе прочего для хранения сложно структурированных данных. Мы привыкли думать, что база данных — это такая таблица, где есть строки и столбцы. Но база данных при правильной организации может намного больше:
- Связывать одну единицу данных с множеством других. Например, если один человек совершил много заказов со множеством товаров внутри каждого, база данных способна хранить и обрабатывать такие связи.
- База может хранить дерево данных — вроде того, о котором мы писали недавно. Попробуй в реальной жизни похранить дерево!
- В базах могут жить ссылки на другие фрагменты и отделы базы.
Базу можно представить как таблицу, но лишь в самом упрощённом виде. Для более сложных задач базу можно представить как очень сложное дерево, или огромный склад упорядоченных коробок, или даже как огромный завод по фасовке данных.
Локальный кэш распределенной информации
В системе слежения за почтовыми отправлениями никогда не требуется доступ ко всей информации сразу. Это обычное явление во всех областях применения: есть вся накопленная и доступная информация, а есть та ее маленькая часть, которая актуальна на конкретный момент времени.
Ничто не мешает веб-ресурсу создать локальный образ распределенной базы данных. Например, пришел посетитель. Еще до того, как он сформулирует запрос, можно подгрузить варианты ответа.
Если есть опыт работы с посетителями из конкретной страны, то может быть известно, из каких стран ожидаются данные.
В некоторых странах система слежения загружена, в основном, локальными запросами (внутри страны), ничто не мешает оптимизировать этот момент, а внешние отправления отдать на откуп другим веб-ресурсам. В некоторых случаях необходимо не только предоставить посетителю внешнюю информацию, но и сопоставить сведения по ответу на один и тот же запрос от разных систем слежения.
Сказать, что в таком случае получится объектно-реляционная модель информации и доступа к ней в определенном смысле возможно, но для реализации этой модели потребуется представить инструмент моделирования действий компаний, работающих в области слежения, то есть развивающих свой функционал.
Процесс проектирования
Дизайн базы данных — это больше искусство, чем наука, так как пользователю придется принимать множество решений. БД обычно настраиваются под конкретное приложение. Нет двух одинаковых пользовательских приложений, и, следовательно, нет двух одинаковых БД. Руководящие принципы обычно указывают на то, что не следует делать, хотя выбор в конечном итоге зависит от дизайнера.
Алгоритм проектирования:
- Определяют цель БД для анализа требований.
- Собирают требования. Выполняют сбор данных, организацию таблиц и указывают первичные ключи.
- Выбирают один или несколько столбцов в качестве так называемого первичного ключа с целью идентификации строк.
- Создают отношения между таблицами. Сила реляционной БД заключается в отношениях между таблицами. Наиболее важным аспектом при разработке РБД является выявление взаимосвязей между ними.
- Необходимо выбрать необходимый тип данных для конкретного столбца. Обычно типы данных содержат: целые числа, строку (или текст), дату, время, двоичный код, коллекцию, например перечисление и набор.
- Уточняют дизайн, добавив больше столбцов.
- Создают новую таблицу для необязательных данных, используя отношение один к одному.
- Разбивают большой стол на два меньших стола.
- Применяют правила нормализации, чтобы проверить, является ли база данных структурно правильной и оптимальной.
- Индекс может быть определен для одного столбца, набора столбцов, называемого составным индексом, или части столбца, называемой частичным индексом. Можно создать более одного индекса в таблице. Например, если часто ищут клиента, используя либо customer Name либо phone Number, можно ускорить поиск, построив индекс по столбцу customer Name, а также phone Number.
- Большинство СУБД автоматически строит индекс по первичному ключу.
Сетевые
В отличие от реляционных баз, в сетевых между таблицами и записями может быть несколько разных связей, каждая из который отвечает за что-то своё.
Если мы возьмём базу данных с сайта Кинопоиска, то она может выглядеть так:

Особенность сетевой базы данных в том, что в ней запоминаются все связи и всё содержимое для каждой связи. Базе не нужно тратить время на поиск нужных данных, потому что вся информация об этом уже есть в специальных индексных файлах. Они показывают, какая запись с какой связана, и быстро выдают результат.
Например, вы посмотрели «Начало» Кристофера Нолана и вам понравился этот фильм. Когда вы перейдёте к списку фильмов, которые он ещё снял, база на сайте сделает так:
- возьмёт имя режиссёра;
- посмотрит, какие связи и с чем у него есть;
- выдаст список фильмов;
- к этим фильмам может сразу подгрузить список актёров, которые там играют;
- и сразу же показать постеры к каждому фильму.
А главное — база сделает это очень быстро, потому что ей не нужно просматривать всю базу в поисках нужных фильмов. Она сразу видит, какие фильмы с чем связаны, и выдаёт ответ.
Проектирование реляционной базы данных. Преобразование модели в реляционную
Преобразование концептуальной модели данных в реляционную — важная часть проектирования БД. Процесс включает в себя:
— построение набора предварительных таблиц;
— указание РК;
— выполнение нормализации.
Из набора таблиц состоят наши объекты, а из полей таблиц — атрибуты объектов:
Итак, мы определились с таблицами, полями, РК и FK. Следует отметить, что в таблицах «Журнал покупок» и «Журнал поставок» РК составные, т. к. состоят из 2-х полей.
Что касается нормализации, то под ней понимают обратимый и пошаговый процесс, при котором исходная схема меняется другой схемой, в которой таблицы характеризуются более простой и логичной структурой. Это нужно по следующим причинам:
1. Устранение избыточности данных. Вспомним нашу таблицу:
Очевидно, что в поле «Темы» одни и те же названия встречаются регулярно. Для хранения таких данных нужны дополнительные ресурсы памяти. Кроме того, при дублировании данных можно допустить ошибку во время ввода значений атрибута, вследствие которой БД перейдёт в состояние несогласованности.
2. Устранение различных аномалий, связанных с обновлением, удалением, модификацией и пр. Пример аномалии модификации — чтобы поменять название темы, нам придётся смотреть все строки и менять название в каждой из них.
Нормализация бывает:
— 1-й нормальной формы (1НФ);
— 2НФ;
— 3НФ;
— НФБК (нормальной формы Бойса-Кодда);
— 4НФ;
— 5НФ.
Каждая форма накладывает определённые ограничения на данные разного уровня. В ходе нормализации база данных становится всё строже, подверженность аномалиям снижается.
Если говорить о реляционных базах данных, то минимум — это 1НФ. Однако в процессе проектирования специалисты по СУБД стремятся нормализовать базу хотя бы до уровня 3НФ, исключив тем самым избыточность данных и аномалии
Это важно, если мы стремимся получить качественный результат проектирования. Однако подробное описание нормализации данных выходит за рамки нашей статьи, поэтому давайте просто посмотрим, как будет выглядеть наша база на уровне 3НФ:
Итак, в процессе проектирования мы преобразовали концептуальную модель в реляционную. Следующий этап — реализация её в конкретной СУБД. Для этого потребуется как сама СУБД, так и знание языка SQL. Например, прекрасно подойдёт СУБД MySQL или какая-нибудь другая СУБД.
Динамичные базы данных
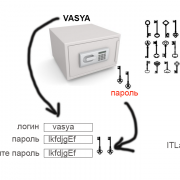
Проблема безопасности привела к проблеме ограничения доступа. Много имен и паролей, много сотрудников и рост числа потерь информации, доступа, персональных данных. Работа ради работы — не самое лучшее решение.
Компания стремится к выполнению своей миссии, а не к тому, чтобы ее служба безопасности поддерживала нормальную работу ее забывчивых сотрудников
Человеческий фактор здесь важно учитывать
Адекватный и востребованный ответ динамичные базы данных, которые моментально захватывают всю инфраструктуру компании и ее сотрудников, автоматом предоставляют каждому, согласно его полномочиям, с любого устройства.

Службы технической поддержки, абонентский сервис, колл-центры — надлежащий ответ разнообразные системы тикетов соединяют в единую базу данных, но не только голосовые и электронные сообщения от клиентов, а также события, вытекающие из работы компании.
Характерная черта современной обработки информации: специалисты научились работать в динамике и использовать статичный потенциал громоздких баз данных в условиях изменчивой потребности.