Функция open() в python, примеры кода
Содержание:
Содержание справочника по Python3:
Определение функций в Python.
Ключевое слово def вводит определение функции . За ним должно следовать имя функции и заключенный в скобки список формальных параметров. Операторы, которые формируют тело функции, начинаются со следующей строки и должны иметь отступ.
Приоритет операций в выражениях в Python.
Выражение — это код, который интерпретатор Python вычисляет для получения значения. Операции с более высоким приоритетом выполняются до выполнения операций с более низким приоритетом.
Строковые и байтовые литералы.
Байтовые литералы всегда начинаются с префикса ‘b’ или ‘B’. Как строковые, так и байтовые литералы могут дополнительно иметь префикс в виде буквы ‘r’ или ‘R’. Такие строки называются необработанными.
Встроенные константы языка Python.
Пространство имен языка Python имеет небольшое количество встроенных констант. Это False, True, None, NotImplemented, __debug__
Инструкция del в Python.
Инструкция `del` не удаляет объекты в буквальном смысле, она лишь открепляет ссылки, разрывая связь между именем и объектом. Удаление объекта произойдет как следствие работы сборщика мусора.
Приемы работы со строками в Python.
Язык программирования Python может манипулировать строками, которые могут быть записаны несколькими способами. Текстовые строки могут быть заключены в одинарные кавычки (‘…’) или двойные кавычки («…»), что в результате будет одно и то же.
Использование регулярных выражений в Python.
Регулярные выражения — это шаблоны соответствия текста, описанные в формальном синтаксисе и могут включать в себя буквальное сопоставление текста, повторение, ветвление и другие сложные правила. Регулярные выражения обычно используются в приложениях, которые требуют тонкую обработку текста.
Использование списков list в Python.
Язык программирования Python имеет несколько составных типов данных, используемых для группировки значений. Наиболее универсальным является список, который можно записать в виде списка значений (элементов), разделенных запятыми, в квадратных скобках.
Использование кортежей tuple в Python.
Кортежи являются неизменяемыми и обычно содержат гетерогенную последовательность элементов, доступ к которым осуществляется через распаковку или индексацию, или даже по атрибуту в случае `collections.namedtuple()`.
Использование словарей dict в Python.
Основные использование словаря — это хранение значения с некоторым ключом и извлечение значения из словаря, заданного ключом. Лучше всего рассматривать словарь как набор пар «ключ-значение» с требованием, чтобы ключи были уникальными в пределах одног
Использование множеств set в Python.
Основные виды использования множеств включают вхождение/наличие элемента и устранение дубликатов записей.
Итераторы в Python.
Функция возвращает объект итератора, который определяет метод __next__(), который, в свою очередь обращается к элементам в контейнере по одному за раз. Когда нет больше элементов, __next__() возбуждает исключение StopIteration
Функция генератора в Python.
Генераторы используют оператор yield всякий раз, когда они хотят вернуть данные. Каждый раз, когда вызывается встроенная функция next(), генератор возобновляет работу с того места, где он остановился.
Работа с файлами в Python.
При доступе к файлу в операционной системе требуется указать путь к файлу. Путь к файлу — это строка, которая представляет местоположение файла.
Система импорта в Python.
При первом импорте модуля Python выполняет поиск модуля и, если он найден, создает объект модуля, инициализируя его. Если именованный модуль не может быть найден, то вызывается исключение ModuleNotFoundError.
Добавление формул
Формулы, начинающиеся со знака равенства, позволяют устанавливать для ячеек значения, рассчитанные на основе значений в других ячейках.
sheet'B9' = '=SUM(B1:B8)'
Эта инструкция сохранит в качестве значения в ячейке . Тем самым для ячейки задается формула, которая суммирует значения, хранящиеся в ячейках от до .
Формула Excel — это математическое выражение, которое создается для вычисления результата и которое может зависеть от содержимого других ячеек. Формула в ячейке Excel может содержать данные, ссылки на другие ячейки, а также обозначение действий, которые необходимо выполнить.
Использование ссылок на ячейки позволяет пересчитывать результат по формулам, когда происходят изменения содержимого ячеек, включенных в формулы. Формулы Excel начинаются со знака . Скобки могут использоваться для определения порядка математических операции.
Примеры формул Excel: =27+36, =А1+А2-АЗ, =SUM(А1:А5), =MAX(АЗ:А5), =(А1+А2)/АЗ.
Хранящуюся в ячейке формулу можно читать, как любое другое значение. Однако, если нужно получить результат расчета по формуле, а не саму формулу, то при вызове функции ей следует передать именованный аргумент со значением .
Python NumPy
NumPy IntroNumPy Getting StartedNumPy Creating ArraysNumPy Array IndexingNumPy Array SlicingNumPy Data TypesNumPy Copy vs ViewNumPy Array ShapeNumPy Array ReshapeNumPy Array IteratingNumPy Array JoinNumPy Array SplitNumPy Array SearchNumPy Array SortNumPy Array FilterNumPy Random
Random Intro
Data Distribution
Random Permutation
Seaborn Module
Normal Distribution
Binomial Distribution
Poisson Distribution
Uniform Distribution
Logistic Distribution
Multinomial Distribution
Exponential Distribution
Chi Square Distribution
Rayleigh Distribution
Pareto Distribution
Zipf Distribution
NumPy ufunc
ufunc Intro
ufunc Create Function
ufunc Simple Arithmetic
ufunc Rounding Decimals
ufunc Logs
ufunc Summations
ufunc Products
ufunc Differences
ufunc Finding LCM
ufunc Finding GCD
ufunc Trigonometric
ufunc Hyperbolic
ufunc Set Operations
Python Tutorial
Python HOMEPython IntroPython Get StartedPython SyntaxPython CommentsPython Variables
Python Variables
Variable Names
Assign Multiple Values
Output Variables
Global Variables
Variable Exercises
Python Data TypesPython NumbersPython CastingPython Strings
Python Strings
Slicing Strings
Modify Strings
Concatenate Strings
Format Strings
Escape Characters
String Methods
String Exercises
Python BooleansPython OperatorsPython Lists
Python Lists
Access List Items
Change List Items
Add List Items
Remove List Items
Loop Lists
List Comprehension
Sort Lists
Copy Lists
Join Lists
List Methods
List Exercises
Python Tuples
Python Tuples
Access Tuples
Update Tuples
Unpack Tuples
Loop Tuples
Join Tuples
Tuple Methods
Tuple Exercises
Python Sets
Python Sets
Access Set Items
Add Set Items
Remove Set Items
Loop Sets
Join Sets
Set Methods
Set Exercises
Python Dictionaries
Python Dictionaries
Access Items
Change Items
Add Items
Remove Items
Loop Dictionaries
Copy Dictionaries
Nested Dictionaries
Dictionary Methods
Dictionary Exercise
Python If…ElsePython While LoopsPython For LoopsPython FunctionsPython LambdaPython ArraysPython Classes/ObjectsPython InheritancePython IteratorsPython ScopePython ModulesPython DatesPython MathPython JSONPython RegExPython PIPPython Try…ExceptPython User InputPython String Formatting
Чтение и запись файлов с использованием Pathlib
Следующие методы используются для выполнения основных операций, таких как чтение и запись файлов:
- : Файл открывается в текстовом режиме для чтения содержимого файла и его закрытия после чтения;
- : Используется для открытия файла в бинарном режиме, возвращения содержимого в бинарном форме и последующего закрытия файла;
- : Используется для открытия файла, записи туда текста и последующего закрытия;
- : Используется для записи бинарных данных в файл и закрытия файла по завершении процесса.
Давайте испытаем модуль Pathlib используя популярные файловые операции. Следующий пример используется для чтения содержимого файла:
Python
path = pathlib.Path.cwd() / ‘Pathlib.md’
path.read_text()
|
1 |
path=pathlib.Path.cwd()’Pathlib.md’ path.read_text() |
Метод для объекта используется для чтения содержимого файла. В примере ниже данные записываются в файл, в текстовом режиме:
Python
from pathlib import Path
p = Path(‘sample_text_file’)
p.write_text(‘Образец данных для записи в файл’)
|
1 |
frompathlib importPath p=Path(‘sample_text_file’) p.write_text(‘Образец данных для записи в файл’) |
Таким образом, в модуле Pathlib наличие пути в качестве объекта позволяет выполнять полезные действия над объектами для файловой системы, включая множество манипуляций с путями, таких как создание или удаление каталогов, поиск определенных файлов, перемещение файлов и так далее.
Заключение
Модуль Pathlib предоставляет огромное количество полезных функций, которые можно использовать для выполнения различных операций, связанных с путями. В качестве дополнительного преимущества библиотека согласовывается с операционной системой.
Способ 2
В качестве хитрого способа создать список в одну строку можно использовать генераторы.
import os
import shutil
import glob
# перейти в папаку RandomFiles
os.chdir('./RandomFiles')
# добавить все файлы в данной папке в список
all_files =
# создать множество расширений имен файлов в этой папке
file_types = set((os.path.splitext(f) for f in all_files))
for ftype in file_types:
new_directory = ftype.replace(".", '')
os.mkdir(new_directory)
for fname in glob.glob(f'*.{ftype}'):
shutil.move(fname, new_directory)
Оба варианта сработают, и все ваши файлы будут отсортированы по расширению.
ManageFiles/
|
|_create_random_files.py
|_RandomFiles/
|_doc
|_docx
|_html
|_md
|_odt
|_ppt
Вот и все. Если вам когда-либо понадобится отсортировать файлы таким образом, вы сэкономите немало времени . Код упражнения доступен здесь.
Текстовые файлы
Последнее обновление: 21.06.2017
Запись в текстовый файл
Чтобы открыть текстовый файл на запись, необходимо применить режим w (перезапись) или a (дозапись). Затем для записи применяется метод write(str),
в который передается записываемая строка. Стоит отметить, что записывается именно строка, поэтому, если нужно записать числа, данные других типов, то их
предварительно нужно конвертировать в строку.
Запишем некоторую информацию в файл «hello.txt»:
with open("hello.txt", "w") as file:
file.write("hello world")
Если мы откроем папку, в которой находится текущий скрипт Python, то увидем там файл hello.txt. Этот файл можно открыть в любом текстовом редакторе и при желании изменить.
Теперь дозапишем в этот файл еще одну строку:
with open("hello.txt", "a") as file:
file.write("\ngood bye, world")
Дозапись выглядит как добавление строку к последнему символу в файле, поэтому, если необходимо сделать запись с новой строки, то можно использовать эскейп-последовательность «\n».
В итоге файл hello.txt будет иметь следующее содержимое:
hello world good bye, world
Еще один способ записи в файл представляет стандартный метод print(), который применяется для вывода данных на консоль:
with open("hello.txt", "a") as hello_file:
print("Hello, world", file=hello_file)
Для вывода данных в файл в метод print в качестве второго параметра передается название файла через параметр file. А первый параметр представляет записываемую
в файл строку.
Чтение файла
Для чтения файла он открывается с режимом r (Read), и затем мы можем считать его содержимое различными методами:
-
readline(): считывает одну строку из файла
-
read(): считывает все содержимое файла в одну строку
-
readlines(): считывает все строки файла в список
Например, считаем выше записанный файл построчно:
with open("hello.txt", "r") as file:
for line in file:
print(line, end="")
Несмотря на то, что мы явно не применяем метод для чтения каждой строки, но в при переборе файла этот метод автоматически вызывается
для получения каждой новой строки. Поэтому в цикле вручную нет смысла вызывать метод readline. И поскольку строки разделяются символом перевода строки «\n», то чтобы исключить излишнего переноса на другую строку в функцию
print передается значение .
Теперь явным образом вызовем метод для чтения отдельных строк:
with open("hello.txt", "r") as file:
str1 = file.readline()
print(str1, end="")
str2 = file.readline()
print(str2)
Консольный вывод:
hello world good bye, world
Метод readline можно использовать для построчного считывания файла в цикле while:
with open("hello.txt", "r") as file:
line = file.readline()
while line:
print(line, end="")
line = file.readline()
Если файл небольшой, то его можно разом считать с помощью метода read():
with open("hello.txt", "r") as file:
content = file.read()
print(content)
И также применим метод readlines() для считывания всего файла в список строк:
with open("hello.txt", "r") as file:
contents = file.readlines()
str1 = contents
str2 = contents
print(str1, end="")
print(str2)
При чтении файла мы можем столкнуться с тем, что его кодировка не совпадает с ASCII. В этом случае мы явным образом можем указать кодировку с помощью
параметра encoding:
filename = "hello.txt"
with open(filename, encoding="utf8") as file:
text = file.read()
Теперь напишем небольшой скрипт, в котором будет записывать введенный пользователем массив строк и считывать его обратно из файла на консоль:
# имя файла
FILENAME = "messages.txt"
# определяем пустой список
messages = list()
for i in range(4):
message = input("Введите строку " + str(i+1) + ": ")
messages.append(message + "\n")
# запись списка в файл
with open(FILENAME, "a") as file:
for message in messages:
file.write(message)
# считываем сообщения из файла
print("Считанные сообщения")
with open(FILENAME, "r") as file:
for message in file:
print(message, end="")
Пример работы программы:
Введите строку 1: hello Введите строку 2: world peace Введите строку 3: great job Введите строку 4: Python Считанные сообщения hello world peace great job Python
НазадВперед
Функции, которые когда-нибудь можно выучить
Следующие встроенные функции Python определённо не бесполезны, но они более специализированы.
Эти функции вам, возможно, будут нужны, но также есть шанс, что вы никогда не прибегнете к ним в своём коде.
- : возвращает итератор (список, набор и т. д.);
- : возвращает , если аргумент является вызываемым;
- and : вместо них рекомендуется использовать генератор-выражения;
- : округляет число;
- : эта функция выполняет деление без остатка () и операцию по модулю () одновременно;
- , и : служат для отображения чисел в виде строки в двоичной, восьмеричной или шестнадцатеричной форме;
- : возвращает абсолютное значение числа (аргумент может быть целым или числом с плавающей запятой, если аргумент является комплексным числом, его величина возвращается);
- ;
- .
Как читать файлы
Python содержит в себе функцию, под названием «open», которую можно использовать для открытия файлов для чтения. Создайте текстовый файл под названием test.txt и впишите:
Python
This is test file
line 2
line 3
this line intentionally left lank
|
1 |
This is test file line 2 line 3 this line intentionally left lank |
Вот несколько примеров того, как использовать функцию «открыть» для чтения:
Python
handle = open(«test.txt»)
handle = open(r»C:\Users\mike\py101book\data\test.txt», «r»)
|
1 |
handle=open(«test.txt») handle=open(r»C:\Users\mike\py101book\data\test.txt»,»r») |
В первом примере мы открываем файл под названием test.txt в режиме «только чтение». Это стандартный режим функции открытия файлов
Обратите внимание на то, что мы не пропускаем весь путь к файлу, который мы собираемся открыть в первом примере. Python автоматически просмотрит папку, в которой запущен скрипт для text.txt
Если его не удается найти, вы получите уведомление об ошибке IOError. Во втором примере показан полный путь к файлу, но обратите внимание на то, что он начинается с «r». Это значит, что мы указываем Python, чтобы строка обрабатывалась как исходная. Давайте посмотрим на разницу между исходной строкой и обычной:
Python
>>> print(«C:\Users\mike\py101book\data\test.txt»)
C:\Users\mike\py101book\data est.txt
>>> print(r»C:\Users\mike\py101book\data\test.txt»)
C:\Users\mike\py101book\data\test.txt
|
1 |
>>>print(«C:\Users\mike\py101book\data\test.txt») C\Users\mike\py101book\data est.txt >>>print(r»C:\Users\mike\py101book\data\test.txt») C\Users\mike\py101book\data\test.txt |
Как видно из примера, когда мы не определяем строку как исходную, мы получаем неправильный путь. Почему это происходит? Существуют определенные специальные символы, которые должны быть отображены, такие как “n” или “t”. В нашем случае присутствует “t” (иными словами, вкладка), так что строка послушно добавляет вкладку в наш путь и портит её для нас. Второй аргумент во втором примере это буква “r”. Данное значение указывает на то, что мы хотим открыть файл в режиме «только чтение». Иными словами, происходит то же самое, что и в первом примере, но более явно. Теперь давайте, наконец, прочтем файл!
Введите нижеизложенные строки в скрипт, и сохраните его там же, где и файл test.txt.
Python
handle = open(«test.txt», «r»)
data = handle.read()
print(data)
handle.close()
|
1 |
handle=open(«test.txt»,»r») data=handle.read() print(data) handle.close() |
После запуска, файл откроется и будет прочитан как строка в переменную data. После этого мы печатаем данные и закрываем дескриптор файла. Следует всегда закрывать дескриптор файла, так как неизвестно когда и какая именно программа захочет получить к нему доступ. Закрытие файла также поможет сохранить память и избежать появления странных багов в программе. Вы можете указать Python читать строку только раз, чтобы прочитать все строки в списке Python, или прочесть файл по частям. Последняя опция очень полезная, если вы работаете с большими фалами и вам не нужно читать все его содержимое, на что может потребоваться вся память компьютера.
Давайте обратим внимание на различные способы чтения файлов. Python
handle = open(«test.txt», «r»)
data = handle.readline() # read just one line
print(data)
handle.close()
Python
handle = open(«test.txt», «r»)
data = handle.readline() # read just one line
print(data)
handle.close()
|
1 |
handle=open(«test.txt»,»r») data=handle.readline()# read just one line print(data) handle.close() |
Если вы используете данный пример, будет прочтена и распечатана только первая строка текстового файла. Это не очень полезно, так что воспользуемся методом readlines() в дескрипторе:
Python
handle = open(«test.txt», «r»)
data = handle.readlines() # read ALL the lines!
print(data)
handle.close()
|
1 |
handle=open(«test.txt»,»r») data=handle.readlines()# read ALL the lines! print(data) handle.close() |
После запуска данного кода, вы увидите напечатанный на экране список, так как это именно то, что метод readlines() и выполняет. Далее мы научимся читать файлы по мелким частям.
Запись информации в файл
Теперь давайте
посмотрим, как происходит запись информации в файл. Во-первых, нам нужно
открыть файл на запись, например, так:
file = open("out.txt", "w")
и далее вызвать
метод write:
file.write("Hello World!")
В результате у
нас будет создан файл out.txt со строкой «Hello World!». Причем, этот
файл будет располагаться в том же каталоге, что и файл с текстом программы на Python.
Далее сделаем
такую операцию: запишем метод write следующим
образом:
file.write("Hello")
И снова выполним
эту программу. Смотрите, в нашем файле out.txt прежнее
содержимое исчезло и появилось новое – строка «Hello». То есть,
когда мы открываем файл на запись в режимах
w, wt, wb,
то прежнее
содержимое файла удаляется. Вот этот момент следует всегда помнить.
Теперь
посмотрим, что будет, если вызвать метод write несколько раз
подряд:
file.write("Hello1")
file.write("Hello2")
file.write("Hello3")
Смотрите, у нас
в файле появились эти строчки друг за другом. То есть, здесь как и со
считыванием: объект file записывает информацию, начиная с текущей файловой
позиции, и автоматически перемещает ее при выполнении метода write.
Если мы хотим
записать эти строчки в файл каждую с новой строки, то в конце каждой пропишем
символ переноса строки:
file.write("Hello1\n")
file.write("Hello2\n")
file.write("Hello3\n")
Далее, для
дозаписи информации в файл, то есть, записи с сохранением предыдущего
содержимого, файл следует открыть в режиме ‘a’:
file = open("out.txt", "a")
Тогда, выполняя
эту программу, мы в файле увидим уже шесть строчек. И смотрите, в зависимости
от режима доступа к файлу, мы должны использовать или методы для записи, или
методы для чтения. Например, если вот здесь попытаться прочитать информацию с
помощью метода read:
file.read()
то возникнет
ошибка доступа. Если же мы хотим и записывать и считывать информацию, то можно воспользоваться
режимом a+:
file = open("out.txt", "a+")
Так как здесь
файловый указатель стоит на последней позиции, то для считывания информации,
поставим его в самое начало:
file.seek() print( file.read() )
А вот запись
данных всегда осуществляется в конец файла.
Следующий
полезный метод для записи информации – это writelines:
file.writelines("Hello1\n", "Hello2\n")
Он записывает
несколько строк, указанных в коллекции. Иногда это бывает удобно, если в
процессе обработки текста мы имеем список и его требуется целиком поместить в
файл.
Запись нескольких DataFrame в файл Excel
Также есть возможность записать несколько DataFrame в файл Excel. Для этого можно указать отдельный лист для каждого объекта:
Копировать
Здесь создаются 3 разных DataFrame с разными названиями, которые включают имена сотрудников, а также размер их зарплаты. Каждый объект заполняется соответствующим словарем.
Объединим все три в переменной , где каждый ключ будет названием листа, а значение — объектом .
Дальше используем движок для создания объекта . Он и передается функции .
Перед записью пройдемся по ключам и для каждого ключа запишем содержимое в лист с соответствующим именем. Вот сгенерированный файл:
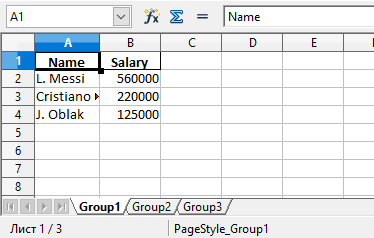
Можно увидеть, что в этом файле Excel есть три листа: Group1, Group2 и Group3. Каждый из этих листов содержит имена сотрудников и их зарплаты в соответствии с данными в трех из кода.

Параметр движка в функции используется для определения модуля, который задействуется библиотекой Pandas для создания файла Excel. В этом случае использовался , который нужен для работы с классом . Разные движка можно определять в соответствии с их функциями.
В зависимости от установленных в системе другими параметрами для движка могут быть (для xlsx или xlsm) и xlwt (для xls). Подробности о модуле можно найти в официальной документации.
Наконец, в коде была строка , которая нужна для сохранения файла на диске.
Данные как ваша отправная точка
Когда вы начинаете проект по data science, вам придется работать с данными, которые вы собрали по всему интернету, и с наборами данных, которые вы загрузили из других мест — Kaggle, Quandl и тд
Но чаще всего вы также найдете данные в Google или в репозиториях, которые используются другими пользователями. Эти данные могут быть в файле Excel или сохранены в файл с расширением .csv … Возможности могут иногда казаться бесконечными, но когда у вас есть данные, в первую очередь вы должны убедиться, что они качественные.
В случае с электронной таблицей вы можете не только проверить, могут ли эти данные ответить на вопрос исследования, который вы имеете в виду, но также и можете ли вы доверять данным, которые хранятся в электронной таблице.
Проверяем качество таблицы
- Представляет ли электронная таблица статические данные?
- Смешивает ли она данные, расчеты и отчетность?
- Являются ли данные в вашей электронной таблице полными и последовательными?
- Имеет ли ваша таблица систематизированную структуру рабочего листа?
- Проверяли ли вы действительные формулы в электронной таблице?
Этот список вопросов поможет убедиться, что ваша таблица не грешит против лучших практик, принятых в отрасли. Конечно, этот список не исчерпывающий, но позволит провести базовую проверку таблицы.
Лучшие практики для данных электронных таблиц
Прежде чем приступить к чтению вашей электронной таблицы на Python, вы также должны подумать о том, чтобы настроить свой файл в соответствии с некоторыми основными принципами, такими как:
- Первая строка таблицы обычно зарезервирована для заголовка, а первый столбец используется для идентификации единицы выборки;
- Избегайте имен, значений или полей с пробелами. В противном случае каждое слово будет интерпретироваться как отдельная переменная, что приведет к ошибкам, связанным с количеством элементов на строку в вашем наборе данных. По возможности, используйте:
- подчеркивания,
- тире,
- горбатый регистр, где первая буква каждого слова пишется с большой буквы
- объединяющие слова
- Короткие имена предпочтительнее длинных имен;
- старайтесь не использовать имена, которые содержат символы ?, $,%, ^, &, *, (,), -, #,? ,,, <,>, /, |, \, , {, и };
- Удалите все комментарии, которые вы сделали в вашем файле, чтобы избежать добавления в ваш файл лишних столбцов или NA;
- Убедитесь, что все пропущенные значения в вашем наборе данных обозначены как NA.
Затем, после того, как вы внесли необходимые изменения или тщательно изучили свои данные, убедитесь, что вы сохранили внесенные изменения. Сделав это, вы можете вернуться к данным позже, чтобы отредактировать их, добавить дополнительные данные или изменить их, сохранив формулы, которые вы, возможно, использовали для расчета данных и т.д.
Если вы работаете с Microsoft Excel, вы можете сохранить файл в разных форматах: помимо расширения по умолчанию .xls или .xlsx, вы можете перейти на вкладку «Файл», нажать «Сохранить как» и выбрать одно из расширений, которые указаны в качестве параметров «Сохранить как тип». Наиболее часто используемые расширения для сохранения наборов данных в data science — это .csv и .txt (в виде текстового файла с разделителями табуляции). В зависимости от выбранного варианта сохранения поля вашего набора данных разделяются вкладками или запятыми, которые образуют символы-разделители полей вашего набора данных.
Теперь, когда вы проверили и сохранили ваши данные, вы можете начать с подготовки вашего рабочего окружения.