Классификация таблиц в реляционных базах данных по признакам целостности и избыточности данных
Содержание:
- Системы Управления Базами Данных
- Как хранится информация в БД
- Фронтальная камера
- Структура данных в реляционной модели данных
- Проектирование баз данных
- Устройство реляционной базы данных – таблицы, строки, столбцы
- Концептуальная модель базы данных
- Пример
- Как выбрать?
- Базы данных: реляционные связи между таблицами
- Базовые и производные отношения
- Жесткие диски цены
- Процесс моделирования и составления основных элементов
- Как ускорить работу компьютера (ноутбука) Windows 7
- Структурная таблица
- Ключи отношения в реляционной модели данных
- Обзор
- Виды баз данных
- Итоги
- Выводы
Системы Управления Базами Данных
Теперь, когда у нас есть реляционная БД, каким образом мы можем её имплементировать? Для этого мы можем воспользоваться системами управления базами данных (СУБД). Существует целый набор подобных программ, как платных, так и бесплатных. Среди платных можно выделить Oracle Database, IBM DB2 и Microsoft SQL Server. Бесплатные: MySQL, SQLite и PostgreSQL.
Чаще всего различные компании используют MySQL. Twitter в этом смысле — не исключение.
SQLite чаще используется при разработке приложений для iOS и Android, где хранится различного рода конфиденциальная информация. Браузер Google Chrome использует SQLite для хранения истории просмотров, кукисов, изображений…
PostgreSQL используется реже. Для неё существует полезное расширение PostGIS, которое делает данную СУБД удобной для хранения геолокационных данных. К примеру сервис OpenStreetMap исользует PostgreSQL.
Как хранится информация в БД
В основе всей структуры хранения лежат три понятия:
- База данных;
- Таблица;
- Запись.
База данных
База данных — это высокоуровневное понятие, которое означает объединение совокупности данных, хранимых для выполнения одной цели.
Если мы делаем современный сайт, то все его данные будут храниться внутри одной базы данных. Для сайта онлайн-дневника наблюдений за погодой тоже понадобится создать отдельную базу данных.
Таблица
По отношению к базе данных таблица является вложенным объеком. То есть одна БД может содержать в себе множество таблиц.
Аналогией из реального мира может быть шкаф (база данных) внутри которого лежит множество коробок (таблиц).
Таблицы нужны для хранения данных одного типа, например, списка городов, пользователей сайта, или библиотечного каталога.
Таблицу можно представить как обычный лист в Excel-таблице, то есть совокупность строк и столбцов.
Наверняка каждый хоть раз имел дело с электронными таблицами (MS Excel).
Заполняя такую таблицу, пользователь определяет столбцы, у каждого из которых есть заголовок. В строках хранится информация.
В БД точно также: создавая новую таблицу, необходимо описать, из каких столбцов она состоит, и дать им имена.
Запись
Запись — это строка электронной таблицы.
Это неделимая сущность, которая хранится в таблице. Когда мы сохраняем данные веб-формы с сайта, то на самом деле добавляем новую запись в какую-то из таблиц базы данных. Запись состоит из полей (столбцов) и их значений. Но значения не могут быть какими угодно.
Определяя столбец, программист должен указать тип данных, который будет храниться в этом столбце: текстовый, числовой, логический, файловый и т.д. Это нужно для того, чтобы в будущем в базу не были записаны данные неверного типа.
Соберем всё вместе, чтобы понять, как будет выглядеть ведение дневника погоды при участии базы данных.
- Создадим для сайта новую БД и дадим ей название «weather_diary».
- Создадим в БД новую таблицу с именем «weather_log» и определим там следующие столбцы:
- Город (тип: текст);
- День (тип: дата);
- Температура (тип: число);
- Облачность (тип: число; от 0 (нет облачности) до 4 (полная облачность));
- Были ли осадки (тип: истина или ложь);
- Комментарий (тип: текст).
- При сохранении формы будем добавлять в таблицу weather_log новую запись, и заполнять в ней все поля информацией из полей формы.
Теперь можно быть уверенными, что наблюдения наших пользователей не пропадут, и к ним всегда можно будет получить доступ.
Реляционная база данных
Английское слово „relation“ можно перевести как связь, отношение.
А определение «реляционные базы данных» означает, что таблицы в этой БД могут вступать в отношения и находиться в связи между собой.
Что это за связи?
Например, одна таблица может ссылаться на другую таблицу. Это часто требуется, чтобы сократить объём и избежать дублирования информации.
В сценарии с дневником погоды пользователь вводит название своего города. Это название сохраняется вместе с погодными данными.
Но можно поступить иначе:
- Создать новую таблицу с именем „cities“.
- Все города в России известны, поэтому их все можно добавить в одну таблицу.
- Переделать форму, изменив поле ввода города с текстового на поле типа «select», чтобы пользователь не вписывал город, а выбирал его из списка.
- При сохранении погодной записи, в поле для города поставить ссылку на соответствующую запись из таблицы городов.
Так мы решим сразу две задачи:
- Сократим объём хранимой информации, так как погодные записи больше не будут содержать название города;
- Избежим дублирования: все пользователи будут выбирать один из заранее определённых городов, что исключит опечатки.
Связи между таблицами в БД бывают разных видов.
В примере выше использовалась связь типа «один-ко-многим», так как одному городу может соответствовать множество погодных записей, но не наоборот!
Бывают связи и других типов: «один-к-одному» и «многие-ко-многим», но они используются значительно реже.
Фронтальная камера
Тут возможны два режима — обычный снимок и «Портрет». Начнём с обычного. Как всегда, первым снимком стала фотография, сделанная на iPhone SE:
Самое заметное отличие — «угол зрения» объектива. Мне пришлось слегка опустить руку с iPhone 11 Pro, чтобы выстроить более грамотный кадр. При этом рука в обоих случаях была вытянута на одинаковое расстояние.
Перейдём к кропу на 250 %:
iPhone 11 Pro нещадно относится к человеку: он очень хорошо отрабатывает тени, они глубокие. Детализация снимка также гораздо лучше, что можно заметить по пыли на очках и в несовершенной и грубой фактуре кожи. Но из-за отработки теней сложно разглядеть зрачок.
Выдержка на обоих айфонах была близкой к 1/380 с, из-за чего мне непонятно, почему я получился на снимке, сделанном на iPhone SE, слегка размытым. Видимо, дело всё-таки не во времени, а в размере и возрасте матрицы, используемой для фронтальной камеры.
И вот тут выходит странная ситуация: как портрет снимок, сделанный на SE, гораздо лучше — цвет кожи приятнее, пропорции близки к реальным. Но качество фотографии лучше всё-таки у iPhone 11 Pro.
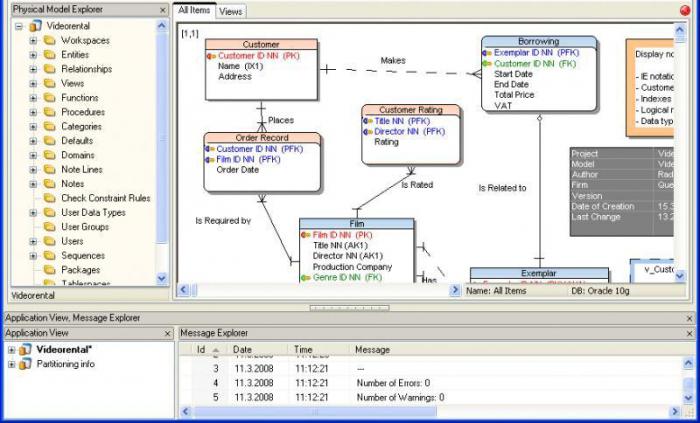
Структура данных в реляционной модели данных
Реляционная модель данных предусматривает структуру данных, обязательными объектами
которой являются:
отношение;
атрибут;
домен;
кортеж;
степень;
кардинальность;
первичный ключ.
Отношение — это плоская (двумерная) таблица, состоящая из столбцов и строк:
| ID | Фамилия | Имя | Должность | г.р. |
| 1 | Петров | Игорь | Директор | 1968 |
| 2 | Иванов | Олег | Юрист | 1973 |
| 3 | Ким | Елена | Бухгалтер | 1980 |
| 4 | Сенин | Илья | Менеджер | 1981 |
| 5 | Васин | Сергей | Менеджер | 1978 |
Атрибут — это поименованный столбец отношения.
Домен — это набор допустимых значений для одного или нескольких атрибутов.
Кортеж — это строка отношения.
Степень определяется количеством атрибутов, которое оно содержит
Кардинальность — это количество кортежей, которое содержит отношение.
Первичный ключ — это уникальный идентификатор для таблицы.
Соответствие между формальными терминами реляционной модели данных и неформальными:
- отношение (формальный термин) — таблица (неформальный термин);
- атрибут — столбец;
- кортеж — строка или запись;
- степень — количество столбцов;
- кардинальное число — количество строк;
- первичный ключ — уникальный идентификатор;
- домен — общая совокупность допустимых значений.
Проектирование баз данных
Проектирование — самая трудная задача при работе с данными. Оно заключается не только в том, чтобы создать таблицу, указав наименование столбцов и тип данных. Это гораздо более сложный процесс, требующий специализированных знаний и умений. Говоря о типах баз данных в столбцах, подразумевается, например, способ их записи, который бывает символьный (строковый), числовой, календарный, NULL.
Основная сложность заключается в том, что мощность наших компьютеров ограничена. И пока данных мало, таблиц и строк тоже немного, поэтому машина обрабатывает информацию достаточно быстро. Но с течением времени информации становится всё больше, что может стать причиной снижения быстродействия. Работа машины будет замедляться, времени на обработку запросов потребуется всё больше. Добавить новую запись в таблицу не станет проблемой для реляционной СУБД, а вот выборка данных может превратиться в весьма ресурсоёмкую операцию. Хотя, многое будет зависеть и от настроек СУБД.
Устройство реляционной базы данных – таблицы, строки, столбцы
Множество это набор уникальных значений, которые закрыты от других множеств (ограничение), не упорядочены (до любого значения можно добраться, не затрагивая другие значения) и уникальны.
Атрибут множества, это название столбца в таблице БД. Математически, атрибут это множество, названий столбцов. Каждое название столбца уникально и неупорядочено. То есть, мы можем «добраться» до уникального названия столбца не затрагивая другие столбцы.
Очень важна уникальность атрибутов (названий столбцов) в рамках базы данных. Достигается уникальность столбцов, добавлением в его названия имя таблицы данных.
О неупорядоченности атрибутов
Математически, множество атрибутов: B.4, B.89, B.55, B.3, B.99, точно такое же, как множество: B.89, B.55, B.4, B.99, B.3. Но на практике, мы не можем вызывать столбцы по названию в произвольном порядке. Для упорядочивания вызова и нужен структурный язык. Для реляционных баз данных структурный язык это язык: SQL. В нем упорядоченный вызов столбцов поатрибутам выглядит так:
SELECT B.4, B.89, B.55, B.3, B.99 FROM B
Или
SELECT B.89, B.55, B.4, B.99, B.3 FROM B
Концептуальная модель базы данных
Под концептуальной моделью понимают отражение предметной области для разрабатываемой базы данных. Если не вдаваться в теорию, то речь идёт о некой диаграмме с общепринятыми обозначениями:
— вещи обозначаются прямоугольниками;
— атрибуты объекта овалами;
— связи в таблицах ромбами;
— мощность и направление связей стрелками (одинарными, двойными).
Делая поставку, поставщик подтверждает её документами. Аналогично и с покупателем. Таким образом, и поставку, и покупку можно рассматривать в качестве самостоятельных объектов.
Итого 5 объектов и 4 связи. Из них:
— 2 связи типа «один ко многим» (один поставщик может делать несколько поставок; один покупатель может делать несколько покупок);
— 2 связи типа «многие ко многим» (каждая поставка может включать несколько товаров, причём одинаковый товар может быть в нескольких поставках; аналогичная ситуация по линии «Покупка — Товар»).
Но давайте вспомним, что связи типа «многие ко многим» недопустимы в реляционных моделях данных, поэтому такие связи надо менять на связи типа «один ко многим». Делаем это, добавляя промежуточный объект:
Видим, что в структуре появились ещё 2 объекта — «Журнал поставок» и «Журнал покупок» со связями типа «один ко многим» (каждый журнал может включать несколько поставок/покупок, но каждая поставка/покупка включает лишь один журнал).
Пример
Пусть заданы следующие типы (домены):
- T1{\displaystyle T_{1}} = {Иванов, Петров, Сидоров}
- T2{\displaystyle T_{2}} = {Физика, Химия}
- T3{\displaystyle T_{3}} = {3, 4, 5}
Тогда декартово произведение T1×T2×T3{\displaystyle T_{1}\times T_{2}\times T_{3}} состоит из 18 кортежей, где каждый кортеж содержит три значения: первое — одна из фамилий, второе — учебная дисциплина, а третье — оценка.
Пусть отношение R имеет заголовок H: { (Фамилия, T1), (Дисциплина, T2), (Оценка, T3)}.
Тогда тело отношения R может моделировать реальную ситуацию и содержать пять кортежей, которые соответствуют результатам сессии (при условии, что Петров экзамен по физике не сдавал). Отобразим отношение в виде таблицы:
| R | ||
|---|---|---|
| Фамилия | Дисциплина | Оценка |
| Иванов | Физика | 4 |
| Иванов | Химия | 3 |
| Петров | Химия | 5 |
| Сидоров | Физика | 5 |
| Сидоров | Химия | 4 |
Как выбрать?
Прежде чем начать выбирать устройство для собственной кухни не помешает для начала разобраться, чем, собственно, отличаются друг от друга модели вытяжек. Для начала стоит отметить, что учитывая предназначение устройств, все они способны работать при достаточно высоких температурах и имеют высокую защиту от горячих паров, конденсата, влаги и высоких температур соответственно.
Разновидности вытяжек классифицируются:
- по принципу работы;
- мощности;
- конструктивным особенностям;
- стоимости.
На последний фактор влияет, прежде всего, наличие дополнительных функций, повышающих производительность устройства и существенно облегчающих жизнь каждой хозяйке.
Можно выделить три основных типа приборов:
- подвесные вытяжки;
- купольные вытяжки;
- встраиваемые вытяжки.
Базы данных: реляционные связи между таблицами
Существует 2 основных вида связей реляционных табличек:
«Один-многие». Возникает при соответствии одной ключевой записи таблицы №1 нескольким экземплярам второй сущности. Значок ключа на одном из концов проведенной линии говорит о том, что сущность находится на стороне «один», второй конец линии зачастую отмечают символом бесконечности.
- Связь «много-много» образуется в случае возникновения между несколькими строками одной сущности явного логичного взаимодействия с рядом записей другой таблицы.
- Если между двумя сущностями возникает конкатенация «один к одному», это значит, что ключевой идентификатор одной таблицы присутствует в другой сущности, тогда следует убрать одну из таблиц, она лишняя. Но иногда исключительно в целях безопасности программисты преднамеренно разделяют две сущности. Поэтому гипотетически связь «один к одному» может существовать.
Базовые и производные отношения
В реляционной базе данных все данные хранятся и доступны через отношения . Отношения, в которых хранятся данные, называются «базовыми отношениями», а в реализациях — «таблицами». Другие отношения не хранят данные, но вычисляются путем применения реляционных операций к другим отношениям. Эти отношения иногда называют «производными отношениями». В реализациях они называются « представлениями » или «запросами». Производные отношения удобны тем, что действуют как одно отношение, даже если они могут получать информацию из нескольких отношений. Кроме того, производные отношения могут использоваться в качестве уровня абстракции .
Домен
Домен описывает набор возможных значений для данного атрибута и может считаться ограничением на значение атрибута. Математически присоединение домена к атрибуту означает, что любое значение атрибута должно быть элементом указанного набора. Например, символьная строка «ABC» находится не в целочисленной области, а целочисленное значение 123 . Другой пример домена описывает возможные значения для поля «CoinFace» как («Головы», «Решки»). Таким образом, поле CoinFace не принимает входные значения, такие как (0,1) или (H, T).
Жесткие диски цены
Процесс моделирования и составления основных элементов
Для того чтобы создать собственную СУБД, следует воспользоваться одним из инструментов моделирования, продумать, с какой информацией вам необходимо работать, спроектировать таблицы и реляционные одно- и множественные связи между данными, заполнить ячейки сущностей и установить первичный, внешние ключи.
Моделирование таблиц и проектирование реляционных баз данных производится посредством бесплатных инструментов, таких как Workbench, PhpMyAdmin, Case Studio, dbForge Studio. После детальной проектировки следует сохранить графически готовую реляционную модель и перевести ее в готовый SQL-код. На этом этапе можно начинать работу с сортировкой данных, их обработку и систематизацию.
Как ускорить работу компьютера (ноутбука) Windows 7
Структурная таблица
Таблица — это логическая структура, состоящая из строк и столбцов. Строки не имеют фиксированного порядка, поэтому, если извлекаются данные, может понадобиться отсортировать их. Порядок столбцов указывается при создании таблицы администратором БД. На пересечении каждого столбца и строки находится определенный элемент данных, называемый значением, или, точнее, атомарным значением. Таблица именуется высокоуровневым классификатором идентификатора пользователя владельца, за которым следует имя таблицы, например TEST.DEPT или PROD.DEPT.
Существует нескольких типов таблиц:
- Базовая, которая создается и содержит постоянные данные.
- Временная, в которой хранятся промежуточные результаты запроса.
Элементы таблиц:
- Столбцы имеют упорядоченный набор: DEPTNO, DEPTNAME, MGR и ADMK DEPT. Все они должны быть однотипными данными.
- Строки — каждая содержит данные для одного отдела.
- Значения на пересечении столбца и строки. Например, PLANNING — это значение столбца DEPT NAME в строке для отдела B01.
Индекс — это упорядоченный набор указателей на строки таблицы. В отличие от строк таблицы, которые не находятся в определенном порядке, индекс DB2 должен всегда поддерживать порядок.
Индекс используется для двух целей:
- Для повышения быстродействия получения значений данных.
- Для уникальности.
Создав индекс по имени сотрудника, можно получить данные для этого сотрудника быстрее, чем сканируя всю таблицу. Кроме того, создавая его, DB2 обеспечит уникальность каждого значения. Создание индекса автоматически создает индексное пространство, набор данных, который его содержит.
Ключи отношения в реляционной модели данных
Ключи отношения могут быть следующми:
- суперключ;
- потенциальный ключ;
- первичный ключ;
- внешний ключ;
- суррогатный ключ.
Ключ отношения — это подсхема исходной схемы отношения, состоящая из одного или
нескольких атрибутов, для которых декларируется условие уникальности значений в кортежах отношений.
При объявлении схемы базового отношения могут быть заданы объявления нескольких ключей.
Ключ отношения может быть простым или составным. Простой ключ – это ключ,
состоящий из одного и не более атрибута. Составной ключ -ключ, состоящий из двух и более атрибутов.
Суперключ — это атрибут или множество атрибутов, которое единственным
образом идентифицирует кортеж данного отношения. Он может включать дополнительные атрибуты. Суперключ
не обладает свойством неизбыточности.
Потенциальный ключ — это подмножество атрибутов отношения, удовлетворяющее требованиям
уникальности и неизбыточности. Он обладает следующими свойствами. Уникальность: в таблице нет двух разных
строк с одинаковыми значениями в нашем потенциальном ключе. Неизбыточность: нельзя убрать один из
столбцов из ключа, так, чтобы он не потерял уникальности. В отношении может быть больше одного
потенциального ключа.
Первичный ключ (primary key, PK) — это один из потенциальных ключей отношения,
выбранный в качестве основного ключа. Допустимо объявление одного и только одного первичного ключа.
Атрибуты первичного ключа не могут принимать значения Null.
Внешний ключ (foreign key, FK) — это ключ, объявленный в базовом отношении,
который при этом ссылается на первичный того же самого или какого-то другого базового отношения.
Суррогатный ключ — это служебный атрибут, добавленный к уже имеющимся информационным
атрибутам отношения. Предназначение суррогатного ключа — служить первичным ключом отношения. Значение
этого атрибута генерируется искусственно.
Пример 2. Есть база данных сети аптек. В ней есть таблица «Аптеки», в
которую занесены все аптеки сети, и есть таблица «Препараты». Кроме того, есть таблица «Наличие», в которую
заносятся данные о наличии препаратов в каждой аптеке. В таблице наличие есть поля: «Аптека» (в ней —
идентификаторы аптек), «Препарат» (в ней — идентификаторы препаратов), «Количество». Возникает проблема:
в случае поступления в аптеку некоторого количества препарата можно не заметить, что в той же аптеке тот
же препарат уже содержится в некотором количестве и сделать новую записись в таблице, в которой аптека и
препарат будут повторяться. Как на уровне ключей избежать этой проблемы?
Решение. Можно объявить первичным ключём таблицы «Наличие» составной ключ, состоящий
из идентификатора аптеки и идентификатора препарата. Тогда в таблице невозможно повторение в разных записях
сочетания аптеки и прапарата. Первичный ключ может быть не только простым, но и
составным.
Обзор
Основная потребность в объектно-реляционной базе данных возникает из-за того, что и реляционная, и объектная база данных имеют свои индивидуальные преимущества и недостатки. Изоморфизм системы реляционных баз данных с математическим соотношением позволяет использовать многие полезные методы и теоремы из теории множеств. Но эти типы баз данных бесполезны, когда дело доходит до сложности данных и несоответствия между приложением и СУБД. Объектно-ориентированная модель базы данных позволяет использовать такие контейнеры, как наборы и списки, произвольные пользовательские типы данных, а также вложенные объекты. Это обеспечивает общность между системами типов приложений и системами типов баз данных, что устраняет любую проблему несоответствия импеданса. Но объектные базы данных, в отличие от реляционных, не предоставляют математической базы для их глубокого анализа.
Основная цель объектно-реляционной базы данных — преодолеть разрыв между реляционными базами данных и методами объектно-ориентированного моделирования, используемыми в таких языках программирования, как Java , C ++ , Visual Basic .NET или C # . Однако более популярной альтернативой для достижения такого моста является использование стандартных систем реляционных баз данных с некоторой формой программного обеспечения объектно-реляционного сопоставления (ORM). В то время как традиционные СУБД или СУБД SQL ориентированы на эффективное управление данными, полученными из ограниченного набора типов данных (определенных соответствующими языковыми стандартами), объектно-реляционные СУБД позволяют разработчикам программного обеспечения интегрировать свои собственные типы и методы, которые применить к ним в СУБД.
ORDBMS (например, ODBMS или OODBMS ) интегрирована с объектно-ориентированным языком программирования . Характерные свойства ORDBMS: 1) сложные данные, 2) наследование типов и 3) поведение объекта. Создание сложных данных в большинстве СУБД SQL основано на предварительном определении схемы через определяемый пользователем тип (UDT). Иерархия в структурированных сложных данных предлагает дополнительное свойство — наследование типов . То есть структурированный тип может иметь подтипы, которые повторно используют все его атрибуты и содержат дополнительные атрибуты, специфичные для этого подтипа. Другое преимущество — поведение объекта — связано с доступом к программным объектам. Такие программные объекты должны быть сохраняемыми и переносными для обработки базы данных, поэтому они обычно называются постоянными объектами . Внутри базы данных все отношения с постоянным программным объектом являются отношениями с его идентификатором объекта (OID) . Все эти моменты можно решить в соответствующей реляционной системе, хотя стандарт SQL и его реализации налагают произвольные ограничения и дополнительную сложность.
В объектно-ориентированном программировании (ООП) поведение объекта описывается с помощью методов (объектных функций). Методы, обозначенные одним именем, различаются по типу их параметров и типу объектов, к которым они прикреплены ( сигнатура метода ). В языках ООП это называется принципом полиморфизма , который кратко определяется как «один интерфейс, множество реализаций». Другие принципы ООП, наследование и инкапсуляция , связаны как с методами, так и с атрибутами. Наследование методов включено в наследование типов. Инкапсуляция в ООП является степень видимости объявлена, например, через , и модификаторы доступа .
Виды баз данных
- Фактографическая – содержит краткую информацию об объектах некоторой системы в строго фиксированном формате;
- Документальная – содержит документы самого разного типа: текстовые, графические, звуковые, мультимедийные;
- Распределённая – база данных, разные части которой хранятся на различных компьютерах, объединённых в сеть;
- Централизованная – база данных, хранящихся на одном компьютере;
- Реляционная – база данных с табличной организацией данных;
- Неструктурированная (NoSQL) — база данных, в которой делается попытка решить проблемы масштабируемости и доступности за счёт атомарности (англ. atomicity) и согласованности данных, но не имеющих четкой (реляционной) структуры.
Одно из основных свойств БД – независимость данных от программы, использующих эти данные. Работа с базой данных требует решения различных задач, основные из них следующие:
- создание базы;
- запись данных в базу;
- корректировка данных;
- выборка данных из базы по запросам пользователя.
Задачи этого списка называются стандартными.
Следующее понятие, связанное с базой данных: программа для работы с базой данных – это программа, которая обеспечивает решение требуемого комплекса задач. Любая подобная программа должна уметь решать все задачи стандартного набора.
База данных в разных системах имеет различную структуру.
В ПВЭМ обычно используются реляционные БД – в таких базах файл является по структуре таблицей. В ней столбцы называются полями, строки – записями.
В БД содержатся банные некоторого множества объктов. Каждая запись содержит данные одного объекта. Каждая такая БД определяется именем файла, списком полей, шириной полей. Например, БД Школа (Ученик, Класс, Адрес).
Примером БД может служить расписание движения поездов или автобусов. Здесь каждая строчка – запись отражает данные строго одного объекта. База включает поля: номер рейса, маршрута следования, время отправления и т.д.
Классическим примером БД является и телефонный справочник. Запрос к базе данных – это предписание, указывающее, какие данные пользователь желает получить из базы.
Некоторые запросы могут представлять собой серьёзную задачу, для решения которой потребляется составлять сложную программу. Например, запрос к базе – автобусному расписанию: определить разницу в среднем интервале отправления автобусов из Ростова в Таганрог и из Ростова в Шахты.
Объекты для работы с базами данных
Для создания приложения, позволяющего просматривать и редактировать базы данных, нам потребуется три звена:
- набор данных
- источник данных
- визуальные элементы управления
В нашем случае эта триада реализуется в виде:
- Table
- DataSource
- DBGrid
Table подключается непосредственно к таблице в базе данных. Для этого нужно установить псевдоним базы в свойстве DataBaseName и имя таблицы в свойстве TableName, а затем активизировать связь: свойство .
Однако, поскольку Table является невизуальным компонентом, хотя связь с базой и установлена, пользователь не в состоянии увидеть какие – либо данные. Поэтому необходимо добавить визуальные компоненты, отображающие эти данные. В нашем случае это сетка DBGrid. Сетка сама по себе «не знает», какие данные ей нужно отображать, её нужно подключить к Table, что и делается через компонент – посредник .
А зачем нужен компонент – посредник? Почему бы сразу не подключаться к Table?
Допустим, несколько визуальных компонентов – таблица, поля ввода и т.п. подключены к таблице. А нам нужно быстро переключить их все на другую подобную таблицу. С DataSource это сделать несложно — достаточно просто поменять свойство t, а вот без пришлось бы менять указатели у каждого компонента.
Приложения баз данных – нить, связывающая БД и пользователя:
БД => набор данных –=> источник данных => визуальные компоненты => пользователь
Набор данных:
- Table(таблица, навигационный доступ)
- Query(запрос, реляционный доступ)
Визуальные компоненты:
- Сетки DBGrid, DBCtrlGrid
- Навигатор DBNavigator
- Всяческие аналоги Lable, Editи т.д.
- Компоненты подстановки
Итоги
- Имеются логические требования к данным, которые могут быть определены заранее.
- Очень важна целостность данных.
- Нужна основанная на устоявшихся стандартах, хорошо зарекомендовавшая себя технология, используя которую можно рассчитывать на большой опыт разработчиков и техническую поддержку.
- Требования к данным нечёткие, неопределённые, или развивающиеся с развитием проекта.
- Цель проекта может корректироваться со временем, при этом важна возможность немедленного начала разработки.
- Одни из основных требований к базе данных — скорость обработки данных и масштабируемость.
Выводы
В пользовательском «общении» с базами данных мы имеем дело, с столбцами, строками, таблицами. Математически в реляционной (табличной) теории их называют: атрибуты, кортежи и отношения. Столбцы могут именоваться колонками (colums), строки могут именоваться записями (records).
Отмечу, чаще приходится иметь дело с такими названиями:
- База данных это таблица (одна или несколько);
- Строки в таблицы, называют запись. Это основная логическая единица БД;
- Столбцы в таблице называют поле. Каждое поле имеет свой тип.
Тип поле определяет тип данных, которые могут быть записаны в этом поле: текст, число, дата, время, валюта и т.п
Пересечение строки и столбца называют ячейка. А это значит, что каждая ячейка входит в запись и имеет свой тип поля.
Пример базы данных MySQL
Возьмем базу данных (таблицы) магазина, вернее одну таблицу базы данных всеx товаров магазина. Для справки это магазин на платформе Moguta, таблица: mg_product.
Это сама база данных состоящая из таблиц.Устройство реляционной базы данных. Это таблица базы данных товаров на сайте.
@WebOnTo.ru