Семантический анализ текста istio
Содержание:
- Как автоматизировать подбор ключевых слов в Вордстате
- Ключевые слова это…
- Краткий обзор SpyWords
- Инструменты для упрощения работы с «Вордстатом» – расширения и программы
- Уточняющий синтаксис в Яндекс Вордстат
- 8 лайфхаков для ресторанного SMM
- Что такое семантическое ядро
- Метод перемножения
- Операторы в Яндекс.Вордстат. Уточняем данные по статистике
- Что можно делать с помощью SQL запросов
- Версии навигатора и системные требования для Андроид
- Зачем нужен Вордстат?
- Программы для анализа плотности слов
- Алгоритм составления семантического ядра
- Ответы на вопросы, хитрости при работе с «Вордстатом»
- Что нужно делать.
- Keyso.so
Как автоматизировать подбор ключевых слов в Вордстате
Даже с помощью плагинов вручную работать с Вордстатом достаточно трудоемко. Но процесс можно автоматизировать. Для этого нам пригодится два инструмента Click.ru:
- Подбор слов и медиапланирование.
- Парсер частотностей Вордстат.
Собираем ключевые слова
Зарегистрируйтесь / авторизуйтесь в Click.ru и откройте инструмент «Подбор слов и медиапланирование».
Укажите базовые данные:
- URL сайта, для которого будете собирать слова;
- место размещения рекламы (поиск, контекстно-медийная сеть или оба варианта).
- регионы, в которых планируете показывать рекламу.
По умолчанию система фиксирует стоп-слова (оператор +, который мы рассматривали выше) и проводит кросс-минусацию. Галочки лучше не снимать.
После указания всех необходимых данных нажмите «Начать новый подбор».
Система проанализирует сайт (URL которого указали на этапе базовых настроек). На основе контента сайта система автоматически подберет релевантные ключевые фразы.
Вы можете добавить к этому списку свои слова или воспользоваться дополнительными инструментами автоматического подбора:
- Слова конкурентов. Здесь нужно будет указать URL сайтов-конкурентов. Система проанализирует их и соберет семантику.
- Слова из счетчиков статистики. Откройте доступ к счетчикам Яндекс.Метрики и/или Google Аналитики. На основе их данных система подберет запросы, по которым к вам на сайт приходили посетители.
Автоматический подборщик слов — это хорошо. Но нам нужны данные Вордстата
Обратите внимание на блок «Ручной подбор слов». Это и есть подборщик на основе данных Вордстата
Как работает подборщик:
1. Введите по одному или списком базовые слова:
Система для каждого слова определяет частотность, а также прогнозы по кликам и бюджету в зависимости от желаемой доли трафика (указываете в столбце «Позиция»).
2. Для просмотра вложенных запросов нажмите на значок списка слева от заданной фразы.
Углубляться можно до тех пор, пока не закончатся вложенные запросы.
3. Просмотрите список подобранных слов. Поставьте галочки на тех, которые вам подходят, и нажмите «Добавить в медиаплан». Вы можете отметить одновременно запросы из ручного и автоматического подборщиков, и добавить в общий список.
Система просчитает бюджет по ключевым словам. Отчет со списком выбранных слов можно скачать в XLSX-формате. При желании можете продолжить настройку — в этом случае система сгенерирует объявления под каждое ключевое слово.
Проверяем частотности Вордстат
С помощью парсера Вордстат можно проверить частотность для списка запросов.
Откройте страницу парсера. Укажите список запросов в поле «Список фраз для проверки»
Также фразы можно загрузить с помощью XLSX-файла (обратите внимание, все запросы должны находиться на первом листе файла, 1 ячейка — 1 запрос)
Далее задайте настройки парсера:
- широкое соответствие;
- оператор «» (фиксирует количество слов в фразе);
- оператор «кавычки» с восклицательным знаком. Фиксирует количество слов в фразе и словоформу каждого слова;
- оператор [] (квадратные скобки). Используется для фиксации порядка слов в фразе.
Поставьте галочки на нужных параметрах (можете проставить галочки на всех четырех). Затем жмите «Запустить проверку». В течение нескольких минут отчет будет готов, и его можно будет скачать в разделе «Список задач».
Отчет скачивается в формате XLSX-файла. Для каждого запроса в таблице указана частотность. Данные по частотности с учетом операторов поиска указаны в отдельных столбцах. Отфильтруйте список и удалите фразы с околонулевой частотностью.
Вот подробный гайд по работе с парсером Вордстат.
Ключевые слова это…
Перед тем как заняться анализом ключевых слов давайте изучим наиболее часто встречающиеся понятия:
- Стратегия ключевых фраз – это методика использования нужных запросов в самом контенте.
- Ключи в тексте – это слова или целые фразы, которые являются своеобразными маяками, за которые цепляется поисковик. Как правило, ключевым словом нередко называют целые фразы, которые могут состоять из 3 и более слов. Само по себе отдельное слово не несёт нужной смысловой нагрузки для поисковых роботов. Для более релевантной выдачи им требуется конкретика.
- Ключевые фразы с хвостами – это именно те запросы, при помощи которых можно отсортировать неподходящие сайты. Именно «хвост» несет основную смысловую нагрузку. Такие фразы чаще всего используются для низкочастотного продвижения сайтов.

Подбор ключевых слов с хвостами
- Главный ключевой запрос – это ядро, вокруг которого формируется сам текст. Такая фраза должна присутствовать в тексте не менее двух раз. Обязательно в первом абзаце и в конце. Фокусное ключевое слово также должно перекликаться с самой тематикой сайта.
- Анализ целевой аудитории (ЦА) – изучение поведения пользователя, его желаний, действий на сайте. В соответствии с полученными данными формируются ключи именно для вашего сайта, товара, предложения.
Краткий обзор SpyWords
Итак, какую информацию о конкурентах можно получить при помощи сервиса?
- Списки ключевых слов;
- Тесты рекламных объявлений Яндекс.Директ и GoogleAdwords;
- Позиции и сниппеты в выдаче;
- Приблизительную оценку трафика и бюджета;
- Совпадающие ключевые слова на конкурирующих сайтах.
На данный момент, на сервисе четыре вкладки:
- Анализ конкурентов;
- Битва доменов;
- Война доменов;
- Умный подбор запросов.
Анализ конкурентов
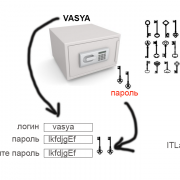
Для анализа конкурентов, можно ввести либо адрес своего сайта, либо поисковую фразу. Предположим, что вы планируете создать сайт «Строим дом своими руками» — вводим запрос и нажимаем кнопку «Отследить».
 В качестве примера, введем запрос «строим дом своими руками»
В качестве примера, введем запрос «строим дом своими руками»
В результате мы получаем следующую информацию:
- Количество показов рекламных объявлений в месяц по Яндексу и Google;
- Количество рекламодателей в Яндексе и Google;
- Среднюю стоимость клика;
- Список рекламодателей и тексты их объявлений.
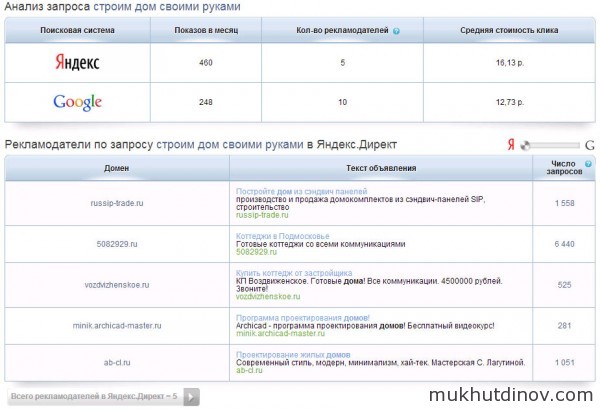 Информация о рекламодателях Яндекс.Директ
Информация о рекламодателях Яндекс.Директ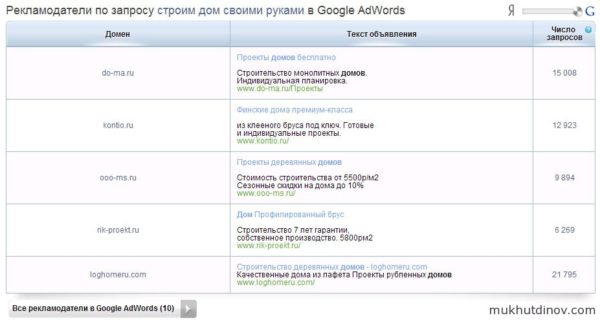 Информация о рекламодателях Google AdWords
Информация о рекламодателях Google AdWords
Также мы получаем список запросов, которые покупают рекламодатели с запросам «строим дом своими руками». На скриншоте ниже видно, что популярностью у рекламодателей пользуется фраза «коттеджи эконом класса в подмосковье», средняя стоимость клика в Яндекс.Директ составляет 165 рублей. Не менее интересен для нас и ТОП выдачи Яндекса и Google.
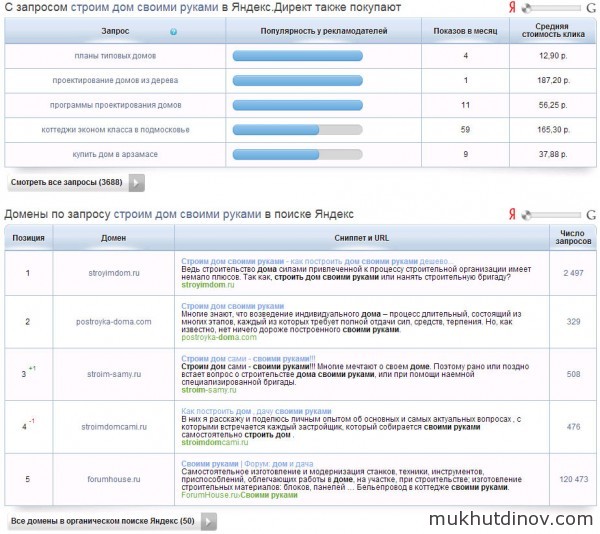
Теперь можно щелкнуть по любому адресу в колонке «Домены» и получить список запросов сайта из ТОП 50 поисковиков. В качестве примера, выберем лидера выдачи Яндекса — stroyimdom.ru.
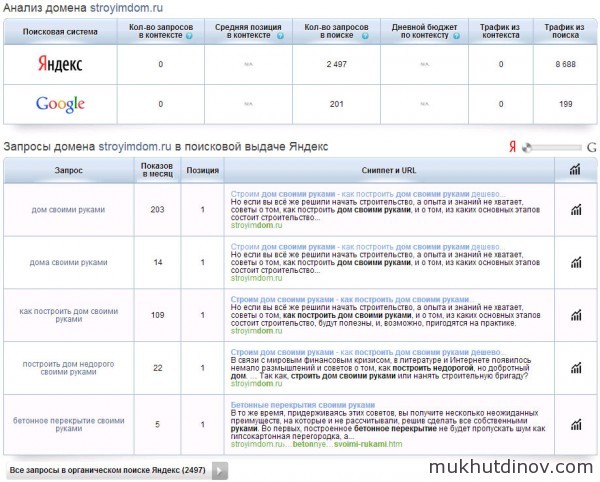 Результат анализа домена stroyimdom.ru
Результат анализа домена stroyimdom.ru
По первой таблице видно, что есть явный перекос в сторону Яндекса — количество запросов в поиске Яндекса 2497, а в поиске Google только 201. Более наглядно это видно на диаграмме.
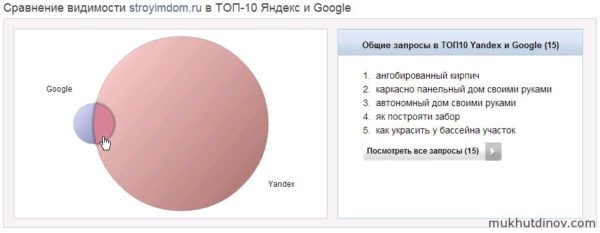 Сравнение видимости сайта в ТОП-10 Яндекс и Google
Сравнение видимости сайта в ТОП-10 Яндекс и Google
Справа от диаграммы, формируется список пересекающихся запросов, т.е. запросов которые находятся в ТОП-10 обоих поисковиков. В конкретном случая таких запросов всего 15.
Список запросов можно экспортировать в формат для Excel (CSV). Если запросов не более 3000, то экспорт произойдет практически мгновенно. При большем количестве запросов, в течение 10 минут, создаются ZIP-архивы, которые можно загрузить из личного кабинета.
 Экспорт запросов в формат CSV
Экспорт запросов в формат CSV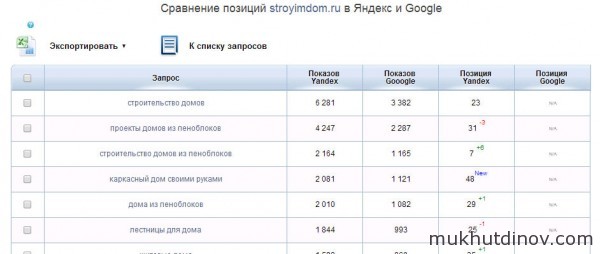 Сравнение позиций сайта в выдаче Яндекса и Google
Сравнение позиций сайта в выдаче Яндекса и Google
Битва доменов
Битва доменов позволяет сравнить между собой три сайта, к примеру сайты ваших конкурентов, и выявить перспективные запросы, которые вы упустили из вида.
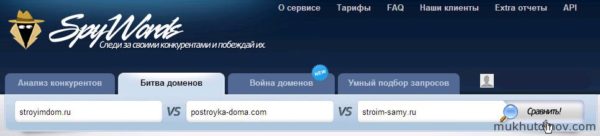 Битва доменов — сравниваем сайты из ТОП-3 Яндекса по запросу «строим дом своими руками»
Битва доменов — сравниваем сайты из ТОП-3 Яндекса по запросу «строим дом своими руками»
Безоговорочным лидером является сайт stroyimdom.ru, так его трафик из поиска намного больше, чем совокупный трафик конкурентов.
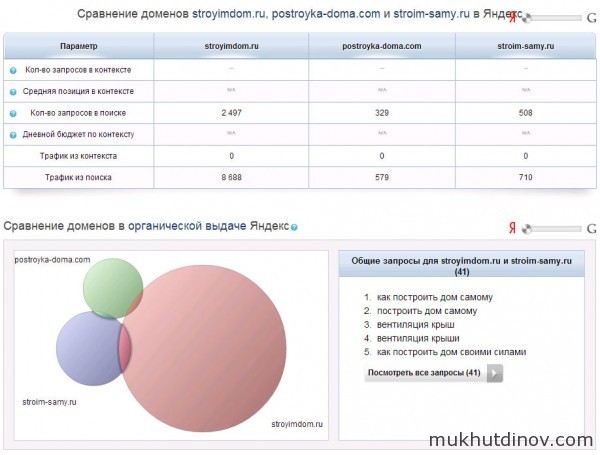 Запросы, общие для конкурирующих сайтов, могут быть перспективными с плане продвижения
Запросы, общие для конкурирующих сайтов, могут быть перспективными с плане продвижения
Для себя мы можем выбрать пересекающиеся запросы, которые, с большой долей вероятности, являются наиболее перспективными в плане продвижения.
Война доменов
Все началось с битвы, а закончилось войной. Война доменов позволят сравнивать показатели большого количества доменов — вплоть до 20 штук. В качестве примера сравним ТОП-5 выдачи Яндекса.
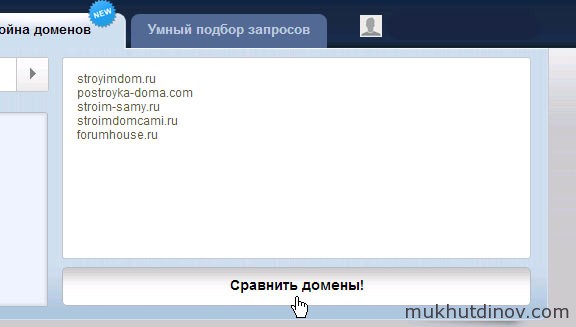 Сравним ТОП-5 выдачи Яндекса по запросу «строим дом своими руками»
Сравним ТОП-5 выдачи Яндекса по запросу «строим дом своими руками»
На выходе получаем сравнение обзорных показателей доменов (количество запросов в поиске, дневной бюджет по контексту, трафик из поиска и контекста и т.д.). Также мы может сравнить запросы исследуемых доменов по разным параметрам, например найти только общие запросы.
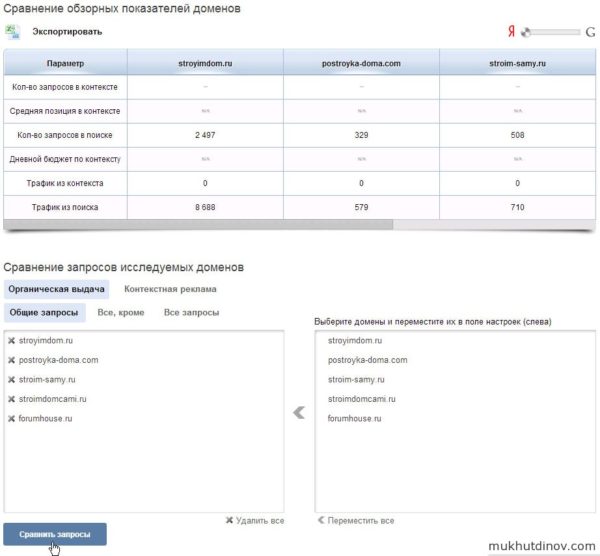 Сравнение показателей большого количества сайтов
Сравнение показателей большого количества сайтов
Умный подбор запросов
Для того, чтобы подобрать самые перспективные (трафик + деньги) в плане продвижения запросы, вводим ключевую фразу на вкладке «Умный подбор запрос» и жмем кнопку «Найти все лучшие слова!».
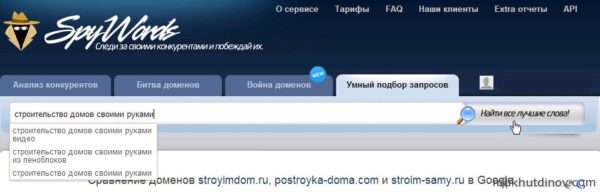 Подбираем наиболее перспективные запросы
Подбираем наиболее перспективные запросы
Сервис подобрал 18 запросов.
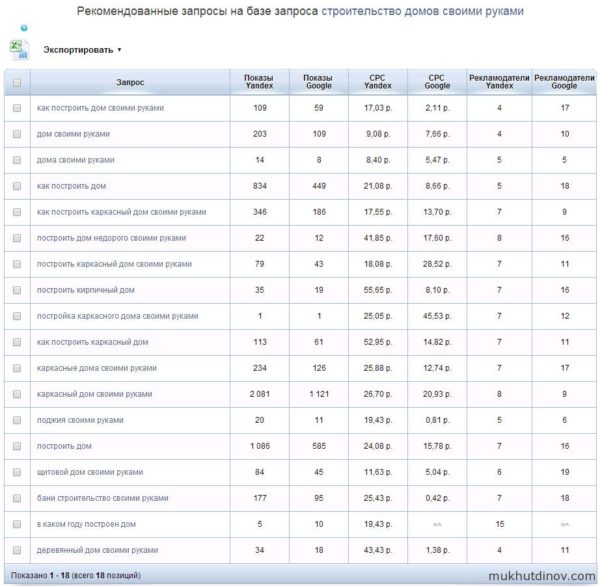 Рекомендованные запросы на базе запроса «строительство домов своими руками»
Рекомендованные запросы на базе запроса «строительство домов своими руками»
Из таблицы видно, что CPC (цена за клик) такого запроса как «лоджия своими руками» в Яндекс в 24 раза больше, чем в Google — это к вопросу «что выгодней, Яндекс.Директ или Google AdSense?». Если вы зарабатываете на контекстной рекламе, то в одних статьях выгодней устанавливать блоки Яндекс.Директ, а в других Google AdSense.
Пара ложек дегтя
Сервис SpyWords может быть весьма полезен для практикующих сеошников. Что касается новичков, то их может отпугнуть цена.
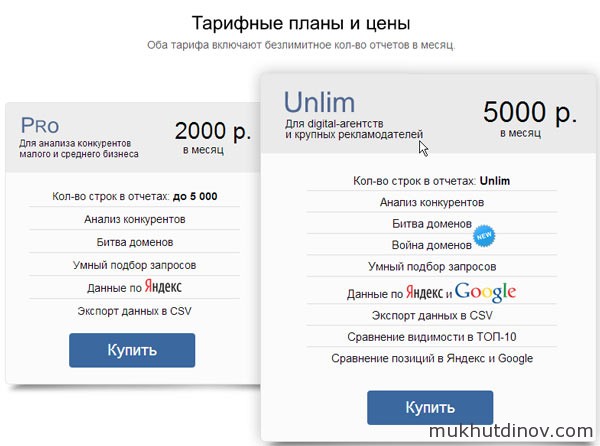 Тарифные планы и цены SpyWords
Тарифные планы и цены SpyWords
К сожалению статистика снимается один раз в месяц — в некоторых случаях это неприемлемо. Однако есть надежда, что по мере развития сервиса, статистика будет обновляться чаще.
Инструменты для упрощения работы с «Вордстатом» – расширения и программы
Работать с «Вордстатом» просто – научиться сносно пользоваться пятью операторами можно за полчаса. А вот собирать большие объемы данных и работать с ними – уже сложнее. В первой части статьи были рассмотрены основы работы с «Вордстатом», потому что без понимания какие данные и почему отдаются сервисом, невозможно эффективно использовать средства автоматизации. Вот три самых популярных программы:
- «Яндекс Вордстат Ассистент»;
- «Яндекс Вордстат Хелпер»;
- «Кей Коллектор» (и его бесплатная версия).
«Яндекс Вордстат Ассистент»
На официальном сайте https://semantica.in/tools/yandex-wordstat-assistant выбираем браузер, который используется для работы. После установки возле каждого запроса появится возможность добавить или удалить его из списка:
Все «проплюсованные» запросы добавляются в список. После того, как все нужные запросы скопированы в список, можно:
- Посмотреть в списке количество добавленных фраз и их суммарную частотность (цифры 2 и 25 над списком на скриншоте выше).
- Скопировать фразы в буфер обмена.
- Скопировать фразы и их частотность в буфер обмена.
- Отсортировать запросы по убыванию или по возрастанию в алфавитном порядке, по порядку добавления в список или по частотности.
Основной плюс – простота использования, дополнение бесплатное. Основной минус – инструмент собирает только фразу и базовую частотность запроса.
«Яндекс Вордстат Хелпер»
Установить дополнение можно также выбрав браузер на странице официального сайта https://arcticlab.ru/yandex-wordstat-helper/
Фактически, это полный аналог предыдущего дополнения, но чуть более удобный (сортировку можно сделать в 1 клик).
Еще один недостаток обоих дополнений – муторная ручная работа при работе с большим количеством запросов. Я уже писал ранее, что популярный запрос может отдавать данные на 40 страницах по убыванию частотности. Чтобы только собрать эти данные, нужно будет произвести более 80 кликов (40 переходов на следующую страницу и 40 добавлений запросов в дополнение).
«Кей Коллектор», описание и настройка парсера данных из «Яндекс.Вордстат»
По сути, это комбайн для работы с данными. Я не буду пересказывать справку программы, а напишу только о плюсах и минусах «Кей Коллектора» при работе с «Вордстатом».
Сначала о минусах. Их всего четыре:
- Как я уже писал, программа платная.
- Потребуется завести отдельные аккаунты в «Яндексе» для «Кей Коллектора», так как при частых автоматических запросах может быть затруднен доступ к «Вордстату» (будет выбиваться несколько капч на каждый запрос).
- Нужно будет 1 раз настроить программу по справке или по скриншотам моих настроек для быстрого сбора данных.
- Потребуется оплатить 1 из сервисов антикапчи, чтобы можно было поставить программу на сбор данных и забыть о ней. Хотя я собираю данные в промышленных объемах (сотни тысяч запросов в месяц), мне на 3 компьютера хватает 150–350 рублей в месяц на оплату антикапча-сервисов.
Теперь интерфейс:
Полный обзор возможностей программы лежит за рамками темы о «Вордстате», потому что краткий видео обзор возможностей программы занимает около полутора часов. Я обозначу только настройки, которые нужны для того, чтобы быстро начать работать с «Вордстатом».
Три волшебных кнопки:
- Сбор фраз из «Яндекс Вордстат». Аналогично тому, как если бы вы руками с каждой страницы копировали запрос и частотность в таблицу.
- Сбор поисковых подсказок. Если вы каждую фразу будете вставлять в поиск и выписывать для нее поисковые подсказки – получите такой же результат, как и программа.
- Сбор частотностей в кавычках «» и с уточнением словоформы «!». Работает так же, как если бы вы каждый запрос вбивали с этими операторами и записывали цифры.
Порядок действий – сначала собираем запросы (1), затем частотность (3). По интересующим запросам собираем подсказки (2) и снова частотность (3).
Полученный результат:
Фактически, сбор десятков тысяч запросов со всеми данными занимает 2-3 часа.
Я приведу настройки, которые нужно сделать, чтобы собирать данные с лучшим сочетанием скорости и дешевизны (не супер быстро, но с небольшим расходом на антикапчу). По порядку:
Сбор разных видов частотностей проходит через «Яндекс.Директ» – настраиваем и его:
Кроме этого в верхней части этого окна нужно добавить несколько аккаунтов «Яндекса»:
И последнее что нужно сделать – зарегистрироваться в любом из совместимых сервисов разгадки капчи, получить в нем код для работы и ввести его в настройках:
Я пробовал разные схемы настроек, эта – самая эффективная и простая.
Остальные 200 кнопок и настроек я предлагаю вам освоить самостоятельно (-:
Существует и бесплатная версия «Кей Коллектора» – программа «Словоеб», которая так же позволяет полноценно работать с «Вордстатом». Ссылка на сайт программы.
Уточняющий синтаксис в Яндекс Вордстат
Давайте снова взглянем на скришот, показывающий статистику по запросу «ключевое слово». На нем мы видим, что данная фраза упоминалась пользователями в поисковике более 62 тысяч раз в течение месяца.
И, кажется, что попадание в ТОП-1 поиска по ней принесет сайту минимум 15-20 тысяч ежемесячного трафика. Забегая вперед, скажу, что в реальной жизни сайт, занимающий первую позицию в поиске по данному запросу, получает по нему не более 200 посетителей – разница в 100 раз это не шутка.
Представьте, что вы вложили в продвижение своего проекта 100 тысяч, рассчитывая, что заработаете 200, а покупателей оказалось в 100 раз меньше и вы заработали 2 тысячи – это провал всего бизнес плана.
Может показаться, что статистика запросов от Яндекс врет и надо искать другой инструмент. Но не спешите, надо просто научиться правильно пользоваться вордстатом.
Есть такая штука – синтаксис поисковых запросов – это когда добавление специальных символов позволяет задавать поисковой системе более точные критерии поиска. Синтаксис запросов работает как в обычном поиске, так и в Yandex Wordstat – давайте учиться его использовать.
1. Исключаем всё лишнее (кавычки)
Первая причина завышенных результатов в статистике запросов – это учет не только той фразы, которую вы ввели в строке сервиса, но и всех фраз в которые она входит.
Обратите внимание, что в примере выше мы видим цифры не только запроса «ключевое слово», но и «ключевые слова яндекс», «статистика ключевых слов» и т.д. Весть этот список суммируется
Но, если мы возьмем наш запрос в кавычки, то все приставки и хвостики в учет не пойдут. Получится вот так:
Теперь мы видим, что цифра в 62 тысячи запросов уменьшилась до 1906 – это существенно ближе к истине, но еще не идеал.
2. Избавляемся от словоформ (восклицательный знак)
Запросы «ключевое слово», «ключевые слова», «ключевом слове» и т.д. мы считаем разными, но поисковая система, по-умолчанию, считает их одним и тем же, что опять размывает статистические данные.
Для того, чтобы исключить из месячных показов ненужные словоформы достаточно поставить перед каждым словом из запроса восклицательный знак, как в примере ниже:
Теперь мы видим всего 411 запросов, но это те самые случаи, когда пользователь ввел только выбранные слова в нужных падежах и склонениях.
3. Соблюдение порядка слов (квадратные скобки)
Еще одна не очевидная фишка поисковика – это безразличие к порядку слов во фразе. Для Яндекс Вордстат запрос «ключевое слово» и «слово ключевое» – одно и то же. В данной фразе этот момент не критичен, но есть запросы, где от порядка слов многое зависит.
За сохранение порядка слов отвечает оператор квадратные скобки ([]).
Такой формат можно считать эталонным.
4. Учет предлогов в статистике (плюс слова)
Следующая особенность поисковых систем – они не учитывают в статистике предлоги. Считается, что эти слова не несут смысловой нагрузки и ими можно пренебречь.
Для учета предлогов придется использовать дополнительный оператор – это знак плюс.
Используя «+» вы можете включать в учет нужные предлоги и отбрасывать фразы их не содержащие. Пишется вот так:
5. Исключение из учета отдельных слов (минус слова)
Нередко возникает необходимость получить общую статистику по фразе, не уточняя её кавычками, но без учета определенных добавок. Например, продавая какую-то услугу, нам необходимо вычислить спрос на нее. Естественно, существуют люди, желающие получить ее бесплатно – их в расчет брать не желательно.
Исключить слово «бесплатно» мы можем оператором «минус». Впрочем, минус удаляет из статистики любое слов стоящее за ним, не только «бесплатно».
Вот как используется данный синтаксис:
Одновременно можно использовать любое количество минус слов, разделяя их пробелами и ставя перед каждым знак “-“.
6. Объединение статистики по схожим запросам
Существует в Вордстате возможность не только уточнять запросы, но и наоборот – объединять данные по схожим фразам.
Как это работает: Допустим, у вас есть 4 ключа, по которым планируется продвижение страницы – это «яндекс вордстат», «yandex wordstat», «яндекс wordstat» и «yandex вордстат».
Мы можем взять общую статистику по всем 4 запросам. Для этого используем круглые скобки и вертикальную черту (прямой слэш). Внутри скобок слэшем разделяем варианты.
Пример: (слово1|слово2) одинаковая часть
Блоков с круглыми скобками может быть несколько, а общая часть может вовсе отсутствовать, как в на скриншоте ниже:
8 лайфхаков для ресторанного SMM
Что такое семантическое ядро
Это список ключевых слов или фраз, инициирующих показ объявления пользователю, который интересуется вашими товарами или услугами. Борьба за клиента начинается именно на уровне семантики: от того, насколько хорошо вы понимаете потенциального клиента, умеете спрогнозировать его поисковые запросы и подобрать те, по которым покажется реклама, — зависит успех и прибыль.
Все способы составления семантического ядра можно условно разделить на две группы.
Первая группа основана на предположении о том, какие запросы могут вводить пользователи. Мы строим догадки и гипотезы, но не прибегаем к дополнительному инструментарию, можем упустить много нужных фраз или придумать лишние — запросы с нулевой частотностью, по которым не будет трафика.
Вторая группа — это способы, основанные на фактических данных и использовании инструментов, позволяющих увидеть реальные запросы пользователей. Они помогают правильно оценить конкурентов, тщательно проработать семантику и составить полное семантическое ядро. В итоге мы сможем показывать рекламные предложения, релевантные запросам пользователей — когда пользователи ищут наш продукт или услугу.
Комбинируя способы из этих двух групп, можно составить правильное и грамотное семантическое ядро, которое подойдет бизнесу и повысит результативность рекламы.
Сбор семантики состоит из нескольких этапов. Чтобы понять общий принцип, давайте подберем ключевые слова для клиента, специализирующегося на доставке цветов в Москве.
Метод перемножения
Шаг 1: расширения масок
Добавляем к базовым маскам расширения из одного слова, чтобы уточнить запрос по разным характеристикам в зависимости от специфики продукта:
Какие категории использовать — решаете сами. Откуда брать варианты? Сайты конкурентов, словари синонимов, тематические форумы и блоги — всё, где можно найти идеи о том, что именно в продукте интересует целевую аудиторию. Это могут быть синонимы, жаргоны, специфическая лексика и т.д.
Всё заносим для удобства в Excel. Получаем по каждому базису примерно такое:
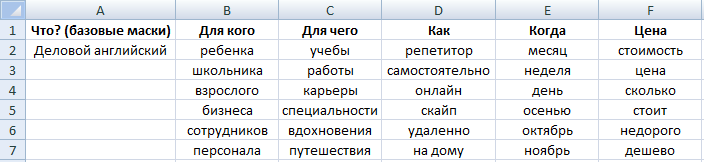
Принцип: 1 ячейка = 1 слово.
Шаг 2: перемножение
Перемножаем первый столбец с остальными по очереди в любом сервисе генерирования ключевых слов:
Результаты переносим на отдельный лист, удаляем нецелевые и ультранизкочастотные запросы.
Операторы в Яндекс.Вордстат. Уточняем данные по статистике
Вордстат собирает статистику по широкому спектру запросов. В выдачу попадает много нерелевантных ключей, а также тех, которые не несут нужного смысла. Для более точного поиска и отсеивания ненужных запросов используют операторы — это специальные знаки, уточняющие параметры подбора слов.
Оператор «»
Кавычки позволяют собирать статистику только по указанному слову или фразе. Например, если ввести уже упомянутый запрос «спальный мешок» — получим статистику 57 164 показов в месяц. Но в это число включены вариации запроса с дополнительными словами: «спальный мешок купить», «спальный мешок цена» и т.д.

Если они вам не нужны, берем запрос в кавычки и получаем статистику только по исходной формулировке.

Просто фразу «спальный мешок» в поиск вбивают куда реже — Вордстат выдает 3 063 показа в месяц.
Оператор !Данный оператор фиксирует форму слова в точном вхождении: без изменения падежа, числа, времени. Например, нам нужно узнать частотность запроса «доставка грузов в Москву» строго в таком вхождении, т.к. другие словоформы изменят смысл фразы.
Вот что Вордстат выдает без оператора:

Используя восклицательный знак, мы получим статистику с точным вхождением слов.

Этот оператор очень полезен при поиске анкоров для ссылок.
Оператор +
Вордстат по умолчанию игнорирует предлоги и союзы, считая их стоп-словами. В некоторых запросах эти части речи имеют принципиальное значение, т.к. без них смысл фразы становится совершенно иным. Оператор + дает указание учитывать все отмеченные предлоги и союзы.
Сравните результаты выдачи с ним и без него:

Без учета предлога Вордстат предлагает нерелевантные запросы.

Задав команду учитывать предлог — получаем статистику по нужному запросу.
Оператор —
Логика работы этого оператора обратная: он убирает из выборки нежелательные слова.
Например, если компания изготавливает только шкафы, то все ключи, связанные с мягкой мебелью или «своими руками» будут засорять статистику. Их убирают при помощи знака минус.
Оператор (|)
Оператор перебора используют для проверки серии похожих запросов.
Например, у нас есть три запроса:
- купить беговые лыжи;
- купить лыжи для конькового хода;
- купить охотничьи лыжи.
Мы можем вводить каждый запрос отдельно, но куда удобнее все сделать в один заход. Для этого группируем слова следующим образом: «купить (беговые|для конькового хода|охотничьи) лыжи».
Таким образом, используя оператор (|) можно не вводить один за другим похожие запросы, а сразу получать сводную статистику. Это очень помогает при сборе семантического ядра, когда нужно собрать частотность по большому количеству похожих запросов.
Оператор
Данный оператор фиксирует порядок слов в запросе.
Например: билет из . Благодаря квадратным скобкам Вордстат не будет предлагать ключи, связанные с направлением Москва-Новосибирск.
Другой пример: запрос бронхита. Оператор фиксирует порядок слов и в выдаче не будет запросов осложнения при лечении бронхита, которые придают фразе совершенной иной смысл.
Совет! Для еще более быстрого и точного сбора запросов некоторые операторы сочетают друг с другом. Например, операторы «» и ! работают в комбинации. При этом команды «» и (|) не сочетаются.
Что можно делать с помощью SQL запросов
Версии навигатора и системные требования для Андроид
Зачем нужен Вордстат?
Инструмент незаменим в таких случаях:
предстоит писать SEO-оптимизированные тексты, для которых важно определить состав ключевых фраз и частотность употребления;
необходимо составить структуру для новой страницы или для всего сайта;
нужно уточнить, какие слова в Вордстат вводят представители целевой аудитории, обращаясь к поисковой системе для решения проблемы, и как именно они формулируют мысли;
требуется выяснить, какие дополнительные интересы имеются у представителей целевой аудитории, чтобы грамотно составить ассортимент товаров и выкладывать максимально полезный контент.
Программы для анализа плотности слов
Кроме он-лайн сервисов для анализа контента на сайте, существуют программы, выполняющие подобные функции. Наиболее известными из них являются:
- Semonitor – мощная программа для решения SEO-задач. В этой программе есть html-анализатор, именно он позволяет проверить плотность ключевых слов на страницах сайта. Программа является платной, цена зависит от версии и количества компонентов. Демо-версию можно скачать на сайте semonitor.ru
- CS Yazzle – программа позволяет собирать внешние ссылки на сайт, анализировать уровень конкуренции по запросам и выполнять ряд других функций, в том числе — выполнять проверку частотности слов на странице. Программа платная, скачать ее можно с сайта yazzle.ru
Мы описали наиболее популярные сервисы для проверки плотности ключевых слов. Формулы расчета плотности у разных сервисов отличаются, как и получаемые результаты. По какой методике считать плотность, учитывать или нет стоп-слова, считать плотность каждой словоформы в отдельности или нет – каждый SEO специалист должен решить сам.
Алгоритм составления семантического ядра
Семантическое ядро – это список всех ключевых фраз, по которым осуществляется продвижение. Мы поговорили о классификации запросов, правилах отбора, инструментах. Теперь нужно разобраться, как составить семантическое ядро.
Подумайте, как Ваши товары и услуги могут искать в поисковых системах. Соберите популярные запросы в Вашей тематике через сервис Яндекс.Вордстат
Обращайте внимание на запросы в правой колонке, поисковые подсказки в результатах поиска. Используйте жаргонные выражения, чтобы найти неочевидные запросы, словари синонимов, «народные» обозначения Ваших товаров или услуг.
Через Сеопульт посмотрите запросы конкурентов, сайты которых имеют высокую посещаемость
Отберите среди запросов конкурентов те, которые подходят для Вашего проекта.
Соберите все запросы в одном файле Excel, отсортируйте по алфавиту и удалите дубли. Запросы, имеющие неправильную структуру и порядок слов с точки зрения русского языка, рекомендую привести в нормальный вид.
Проверьте частоту запросов в кавычках. Если запросов много, используйте инструмент Топвизор. Удалите из списка запросы с нулевой частотой в кавычках.
Проверьте полученный список запросов еще раз. Удалите фразы, которые не подходят.
Полезный совет. Иногда конкуренты забывают закрывать доступ от систем статистики на своих сайтах. Если кто-то из конкурентов забыл закрыть доступ к своей статистике, посмотрите в ней, по каким запросам переходят на сайт конкурента.
Ответы на вопросы, хитрости при работе с «Вордстатом»
За годы работы с «Вордстатом» у меня накопилась небольшая методичка по ответам на часто задаваемые неочевидные вопросы. Думаю, вы найдете что-то полезное.
Собрали кучу данных
Как проводить анализ запросов? На что обращать внимание?. В первую очередь обращаем внимание на коммерческие запросы, у которых частота без кавычек и в кавычках отличается плюс-минус в 2 раза или менее
Если при еще и слабая выдача (нет нормальных предложений), вообще отлично
В первую очередь обращаем внимание на коммерческие запросы, у которых частота без кавычек и в кавычках отличается плюс-минус в 2 раза или менее. Если при еще и слабая выдача (нет нормальных предложений), вообще отлично
Чем больше расхождение в цифрах, тем больше у вас шанс не угадать намерение пользователя. Например, запрос «боковое стекло хендай» плохой, потому вообще непонятно, что ищут. Дефлектор бокового стекла? Само стекло? Левое? Правое? Переднее? Купить или продать?
Пример хорошего запроса:

2. Как посмотреть статистику запросов для одного города?
Выберите свой город в настройках региона. Помимо города хорошо бы понимать целевую аудиторию и дополнительно затачивать сайт под целевую аудиторию. Например, эвакуатор или вскрытие дверей почти наверняка будут искать со смартфона или планшета.
3. Как обойти ограничение на длину запроса в 8 слов?
Через «Вордстат» такие данные собрать нельзя. Запросы из 8 и более слов можно собрать в поисковых подсказках, найти в различных базах запросов или получить в статистике своего сайта.
4. Что означают абсолютные и относительные данные в истории запросов?
Абсолютный показатель – это фактическое цифровое значение, сколько было таких запросов за период. Относительное значение показывает популярность запроса среди всех запросов в поиске.

5. Что делать, если «Вордстат» собрал 2000 запросов, но нужно больше?
В широких нишах на 40-й странице «Вордстата» только начинается самое интересное:

Если в «Вордстат» ввести запрос в кавычках, повторяя основное слово, вы увидите все запросы из Х слов, содержащих нужное слово. Х – количество слов во фразе в кавычках. Пример:

Используя поочередно конструкции:
- «налог налог налог налог налог налог налог»
- «налог налог налог налог налог налог»
- «налог налог налог налог налог»
- «налог налог налог налог»
- «налог налог налог»
- «налог налог»
- налог
Можно собрать все запросы, которые содержат слово «налог» или его склонения.
6. Как провести массовую проверку частотности запросов из «Вордстат»?
Массово проверить все частотности фраз можно сделать в «Кей Коллекторе» или его бесплатном аналоге – программе «Словоеб».
7. Как убрать капчу в «Вордстате»?
Причина появления капчи – большое количество запросов с 1 IP адреса. Вы можете или сменить айпишник, или использовать программы для работы с «Вордстатом» вместе с сервисами разгадывания капчи.
8. Почему у «Вордстата» ограничение длины в 7 слов?
«Вордстат» изначально был создан как сервис статистики для «Яндекс Директа», в котором максимальное количество слов в рекламной фразе – 7. Никаких других причин для ограничения запроса нет.
Источник статьи

Что нужно делать.
Поэтому при сборе семантики, при сборе ключевых слов для Директа, нужно отталкиваться от логики.
Нужно использовать горячие запросы, их тестировать, использовать запросы с указанием точного наименования товара, именно те запросы, которые характеризуют намерения покупатели приобрести или заказать какой-то товар.
Во вторую группу запросов можно определять некие информационные запросы, но здесь уже нужно тестировать и смотреть, будут ли по ним продажи.
Но первую ставку нужно делать именно на горячие запросы. А не раздувать свою рекламную кампанию, чтобы она была непомерно большой.
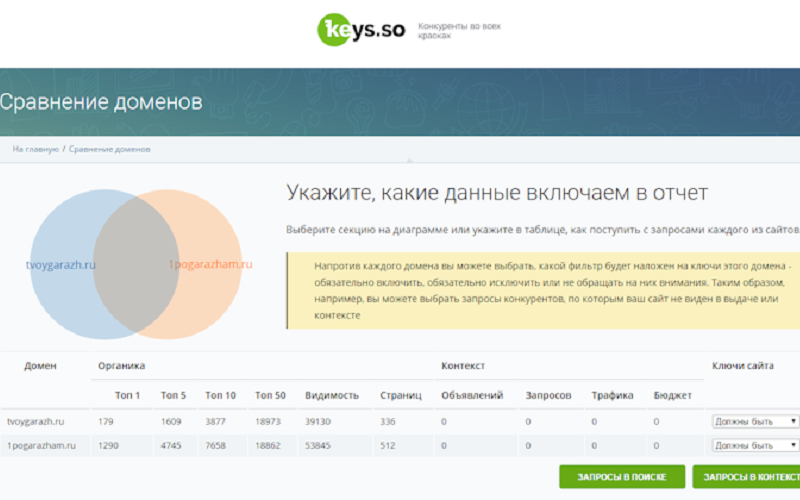
Keyso.so
Сервис Keyso.so позволяет находить подходящие ключевые слова, анализировать нишу сайта, планировать работы по продвижению сайта или разработке контекстной рекламы.
Возможности Keyso.so:
- Анализ позиции сайта по ключевым словам и словосочетаниям;
- Анализ сайтов-конкурентов по популярности в поиске или по ключевым словам;
- Анализ рекламных кампаний сайтов-конкурентов;
- Формирование групповых отчётов с большим количеством доменов в одном отчёте, а также фильтрация данных по тематичности;
- Анализ данных Яндекса по заданным регионам.
Тарифы Keyso.so:
- Стартовый (за 1 месяц) – 1,5 тыс. рублей (при оплате за год стоимость составит 1,05 тыс. рублей);
- Базовый (за 1 месяц) – 4,8 тыс. рублей (при оплате за год стоимость составит 3,36 тыс. рублей);
- Корпоративный (за 1 месяц) – 14,5 тыс. рублей (при оплате за год стоимость составит 10,15 тыс. рублей).