Язык запросов sql
Содержание:
- Запрос обновления данных (update)
- SQL Справочник
- Создание запросов.
- Обновление (UPDATE)
- Инструкция USE
- Команда HOST
- Допустим, что вы дошли до этого момента
- Соединения (джойны)
- 5. Агрегирование
- 6. Подзапросы
- Запрос для удаления данных (delete)
- Запрос вставки (insert)
- Тинькофф Инвестиции от Тинькофф Брокер. Достоинства
- Выражение CASE – условный оператор языка SQL
- Инструкция SHOW
- Выборка информации
- Типы данных и выражения sql
- Команда SPOOL
- Оператор join: объединение записей из двух таблиц
- Команды ACCEPT и PROMPT
- Что такое язык SQL и оператор SELECT
- Оператор update: обновление информации в БД
- Что это такое
- Общая характеристика языка запросов SQL
Запрос обновления данных (update)
Запрос обновления данных строится следующим образом:
update table set col1 = val1, col2 = val2, ..., colN = valN where clause;
где update — это начало sql-запроса, table — это конкретное имя таблицы, set — обозначает, что далее будет список требуемых изменений, col1 = val1, col2 = val2, …, colN = valN — это перечисление через запятую колонок с присваиваемыми им значениями, where — указывает, что далее будут перечислены условия отбора, clause — условие фильтра (аналогично delete). Запрос так же заканчивается точкой с запятой.
Примечание: Важно отметить, что часть where с clause являются необязательными. То есть, если фильтр не требуется, то их можно не писать
Однако, если фильтр нужен, то обе составляющих необходимо использовать в запросе.
К примеру, если необходимо не удалить все строки из примера ранее, а указать для всех этих строк дату рождения 31.12.2222 и возраст -203, то sql-запрос выглядел бы так:
update somedata set Age = -203, Date = '31.12.2222' where (Age > 1 and Age < 5) or Name = 'Масяня';
Обратите внимание, что поля Age и Date изменяются только после проверки условий фильтра
Это важно, так как запрос позволяет использовать текущие значения колонок при фильтрации (иначе бы могли возникать несоответствия)
SQL Справочник
SQL Ключевые слова
ADD
ADD CONSTRAINT
ALTER
ALTER COLUMN
ALTER TABLE
ALL
AND
ANY
AS
ASC
BACKUP DATABASE
BETWEEN
CASE
CHECK
COLUMN
CONSTRAINT
CREATE
CREATE DATABASE
CREATE INDEX
CREATE OR REPLACE VIEW
CREATE TABLE
CREATE PROCEDURE
CREATE UNIQUE INDEX
CREATE VIEW
DATABASE
DEFAULT
DELETE
DESC
DISTINCT
DROP
DROP COLUMN
DROP CONSTRAINT
DROP DATABASE
DROP DEFAULT
DROP INDEX
DROP TABLE
DROP VIEW
EXEC
EXISTS
FOREIGN KEY
FROM
FULL OUTER JOIN
GROUP BY
HAVING
IN
INDEX
INNER JOIN
INSERT INTO
INSERT INTO SELECT
IS NULL
IS NOT NULL
JOIN
LEFT JOIN
LIKE
LIMIT
NOT
NOT NULL
OR
ORDER BY
OUTER JOIN
PRIMARY KEY
PROCEDURE
RIGHT JOIN
ROWNUM
SELECT
SELECT DISTINCT
SELECT INTO
SELECT TOP
SET
TABLE
TOP
TRUNCATE TABLE
UNION
UNION ALL
UNIQUE
UPDATE
VALUES
VIEW
WHERE
MySQL Функции
Функции строк
ASCII
CHAR_LENGTH
CHARACTER_LENGTH
CONCAT
CONCAT_WS
FIELD
FIND_IN_SET
FORMAT
INSERT
INSTR
LCASE
LEFT
LENGTH
LOCATE
LOWER
LPAD
LTRIM
MID
POSITION
REPEAT
REPLACE
REVERSE
RIGHT
RPAD
RTRIM
SPACE
STRCMP
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TRIM
UCASE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATAN2
AVG
CEIL
CEILING
COS
COT
COUNT
DEGREES
DIV
EXP
FLOOR
GREATEST
LEAST
LN
LOG
LOG10
LOG2
MAX
MIN
MOD
PI
POW
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SUM
TAN
TRUNCATE
Функции дат
ADDDATE
ADDTIME
CURDATE
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURTIME
DATE
DATEDIFF
DATE_ADD
DATE_FORMAT
DATE_SUB
DAY
DAYNAME
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FROM_DAYS
HOUR
LAST_DAY
LOCALTIME
LOCALTIMESTAMP
MAKEDATE
MAKETIME
MICROSECOND
MINUTE
MONTH
MONTHNAME
NOW
PERIOD_ADD
PERIOD_DIFF
QUARTER
SECOND
SEC_TO_TIME
STR_TO_DATE
SUBDATE
SUBTIME
SYSDATE
TIME
TIME_FORMAT
TIME_TO_SEC
TIMEDIFF
TIMESTAMP
TO_DAYS
WEEK
WEEKDAY
WEEKOFYEAR
YEAR
YEARWEEK
Функции расширений
BIN
BINARY
CASE
CAST
COALESCE
CONNECTION_ID
CONV
CONVERT
CURRENT_USER
DATABASE
IF
IFNULL
ISNULL
LAST_INSERT_ID
NULLIF
SESSION_USER
SYSTEM_USER
USER
VERSION
SQL Server функции
Функции строк
ASCII
CHAR
CHARINDEX
CONCAT
Concat with +
CONCAT_WS
DATALENGTH
DIFFERENCE
FORMAT
LEFT
LEN
LOWER
LTRIM
NCHAR
PATINDEX
QUOTENAME
REPLACE
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
STUFF
SUBSTRING
TRANSLATE
TRIM
UNICODE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATN2
AVG
CEILING
COUNT
COS
COT
DEGREES
EXP
FLOOR
LOG
LOG10
MAX
MIN
PI
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SQUARE
SUM
TAN
Функции дат
CURRENT_TIMESTAMP
DATEADD
DATEDIFF
DATEFROMPARTS
DATENAME
DATEPART
DAY
GETDATE
GETUTCDATE
ISDATE
MONTH
SYSDATETIME
YEAR
Функции расширений
CAST
COALESCE
CONVERT
CURRENT_USER
IIF
ISNULL
ISNUMERIC
NULLIF
SESSION_USER
SESSIONPROPERTY
SYSTEM_USER
USER_NAME
MS Access функции
Функции строк
Asc
Chr
Concat with &
CurDir
Format
InStr
InstrRev
LCase
Left
Len
LTrim
Mid
Replace
Right
RTrim
Space
Split
Str
StrComp
StrConv
StrReverse
Trim
UCase
Функции чисел
Abs
Atn
Avg
Cos
Count
Exp
Fix
Format
Int
Max
Min
Randomize
Rnd
Round
Sgn
Sqr
Sum
Val
Функции дат
Date
DateAdd
DateDiff
DatePart
DateSerial
DateValue
Day
Format
Hour
Minute
Month
MonthName
Now
Second
Time
TimeSerial
TimeValue
Weekday
WeekdayName
Year
Другие функции
CurrentUser
Environ
IsDate
IsNull
IsNumeric
SQL ОператорыSQL Типы данныхSQL Краткий справочник
Создание запросов.
SELECT используется для получение данных. Давайте получим значения столбца user и pass .
Или получим всю таблицу :
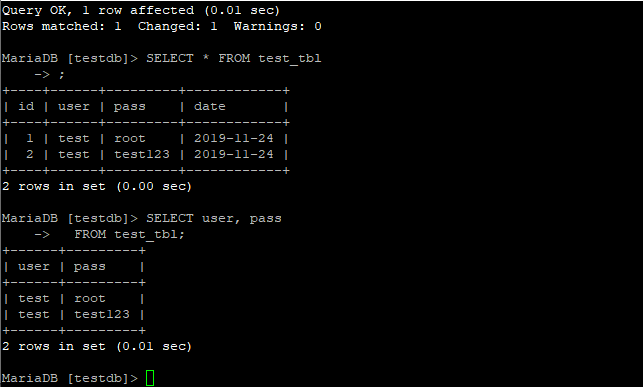
В столбцах таблицы могут содержаться повторяющиеся данные. Используйте SELECT DISTINCT для получения только неповторяющихся данных.
WHERE
В запросе мы можем использовать всяко разные условия. Выведем например все данные где user = ‘test’ :
- сравнение текста;
- сравнение численных значений;
- логические операции AND (и), OR (или) и NOT (отрицание).
ORDER BY
ORDER BY используется для сортировки результатов запроса по убыванию или возрастанию. ORDER BY отсортирует по возрастанию, если не будет указан способ сортировки ASC или DESC.

BETWEEN
С помощью BETWEEN мы можем выбрать определенный промежуток. Могут использованы числовые и текстовые значения, а также даты. Например с 2 по 4 запись :
LIKE
Оператор LIKE используется в WHERE, чтобы задать шаблон поиска похожего значения.
- _ — Подчеркнутый символ представляет собой один символ .
- % — Знак процента представляет нулевой, один или несколько символов.
- WHERE name LIKE ‘text%’ : Находит любые значения, начинающиеся с «text» .
- WHERE name LIKE ‘%text’ : Находит любые значения, заканчивающиеся на «text» .
- WHERE name LIKE ‘%text%’ : Находит любые значения, которые имеют «text» в любой позиции .
- WHERE name LIKE ‘_text%’ : Находит любые значения, которые имеют «text» во второй позиции .
- WHERE name LIKE ‘text_%_%’ : Находит любые значения, начинающиеся с «text» и длиной не менее 3 символов .
- WHERE name LIKE ‘text%data’ : Находит любые значения, начинающиеся с «text» и заканчивающиеся на «data» .
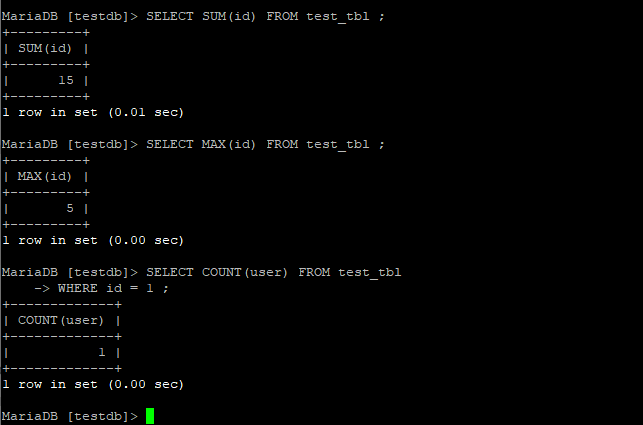
Агрегатные функции
- COUNT (Имя столбца) — возвращает количество строк
- SUM ( Имя столбца ) — возвращает сумму значений в данном столбце
- AVG ( Имя столбца ) — возвращает среднее значение данного столбца
- MIN ( Имя столбца ) — возвращает наименьшее значение данного столбца
- MAX ( Имя столбца ) — возвращает наибольшее значение данного столбца
Обновление (UPDATE)
Синтаксис:
> UPDATE <table> SET <field>='<value>’ WHERE <conditions>
* где table — имя таблицы; field — поле, для которого будем менять значение; value — новое значение; conditions — условие (без него делать update опасно — можно заменить все данные во всей таблице).
Обновление с использованием замены (REPLACE):
UPDATE <table> SET <field> = REPLACE(<field>, ‘<что меняем>’, ‘<на что>’);
Примеры:
UPDATE cities SET name = REPLACE(name, ‘Масква’, ‘Москва’);
UPDATE cities SET name = REPLACE(name, ‘Масква’, ‘Москва’) WHERE country = ‘Россия’;
UPDATE cities SET name = REPLACE(name, ‘Ма’, ‘Мо’) WHERE name = ‘Масква’;
Если мы хотим перестраховаться, результат замены можно сначала проверить с помощью SELECT:
SELECT REPLACE(name, ‘Ма’, ‘Мо’) FROM cities WHERE name = ‘Масква’;
Инструкция USE
Для того, чтобы начать взаимодействие с какой-либо базой данных, необходимо подключиться к ней. Для этого существует команда . Посмотрим пример:
INI
MariaDB > USE lexone.ru;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
|
1 2 3 4 |
MariaDB>USElexone.ru; Readingtableinformationforcompletionoftableandcolumnnames Youcanturnoffthisfeaturetogetaquickerstartupwith-A Databasechanged |
Но перед тем, как подключаться к базам данных, нужно узнать, какие-же вообще есть базы данных на нашем сервере. Нельзя подключиться к тому, сам не знаю к чему. Для этого используется инструкция .
Команда HOST
Команда позволяет выполнять в SQL*Plus команды операционной системы.Например, может возникнуть необходимость посмотреть, существует ли некий файл в определенном каталоге, или выдать команды или на уровне , а затем вернуться в сеанс SQL*Plus и возобновить взаимодействие с базой данных Oracle.
Ниже приведен пример применения команды :
SQL> HOST cp /u01/app/oracle/new.sql /tmp
В этом примере команда помогает скопировать файл из указанного каталога в каталог .
С помощью команды можно выполнять практически все те же команды, которые доступны на уровне операционной системы. Слово можно заменять восклицательным знаком (!):
SQL> ! cp /u01/app/oracle/new.sql /tmp
На заметку! В случае ввода команды HOST без параметров вы попадаете в каталог операционной системы, из которого изначально запускали сеанс SQL*Plus.
По завершении работы с операционной системой достаточно ввести в командной строке и на экране снова появится приглашение покинутого ранее сеанса SQL*Plus.
Например:
SQL> HOST $ exit SQL>
Допустим, что вы дошли до этого момента
- Выбирать детальные данные по условию WHERE из одной таблицы
- Умеете пользоваться агрегатными функциями и группировкой из одной таблицы
| ID | Name | Birthday | … | Salary | BonusPercent | DepartmentName | PositionName |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 19.02.1955 | 5000 | 50 | Администрация | Директор | |
| 1001 | Петров П.П. | 03.12.1983 | 1500 | 15 | ИТ | Программист | |
| 1002 | Сидоров С.С. | 07.06.1976 | 2500 | NULL | Бухгалтерия | Бухгалтер | |
| 1003 | Андреев А.А. | 17.04.1982 | 2000 | 30 | ИТ | Старший программист | |
| 1004 | Николаев Н.Н. | NULL | 1500 | NULL | ИТ | Программист | |
| 1005 | Александров А.А. | NULL | 2000 | NULL | NULL | NULL |
| ID | Name | Birthday | … | Salary | BonusPercent | DepartmentName | PositionName |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 19.02.1955 | 5000 | 50 | Администрация | Директор | |
| 1001 | Петров П.П. | 03.12.1983 | 1500 | 15 | ИТ | Программист | |
| 1002 | Сидоров С.С. | 07.06.1976 | 2500 | NULL | Бухгалтерия | Бухгалтер | |
| 1003 | Андреев А.А. | 17.04.1982 | 2000 | 30 | ИТ | Старший программист | |
| 1004 | Николаев Н.Н. | NULL | 1500 | NULL | ИТ | Программист | |
| 1005 | Александров А.А. | NULL | 2000 | NULL | NULL | NULL |
| DepartmentName | PositionCount | EmplCount | SalaryAmount | SalaryAvg |
|---|---|---|---|---|
| NULL | 1 | 2000 | 2000 | |
| Администрация | 1 | 1 | 5000 | 5000 |
| Бухгалтерия | 1 | 1 | 2500 | 2500 |
| ИТ | 2 | 3 | 5000 | 1666.66666666667 |
| ID | Name | Salary |
|---|---|---|
| 1005 | Александров А.А. | 2000 |
| 1003 | Андреев А.А. | 2000 |
| 1000 | Иванов И.И. | 5000 |
| 1004 | Николаев Н.Н. | 1500 |
| 1001 | Петров П.П. | 1500 |
| 1002 | Сидоров С.С. | 2500 |
Соединения (джойны)
Теперь мы хотим увидеть названия (не обязательно уникальные) всех книг Дэна Брауна, которые были взяты из библиотеки, и когда эти книги нужно вернуть:
Результат:
| Title | Return Date |
|---|---|
| The Lost Symbol | 2016-03-23 00:00:00 |
| Inferno | 2016-04-13 00:00:00 |
| The Lost Symbol | 2016-04-19 00:00:00 |
По большей части запрос похож на предыдущий за исключением секции . Это означает, что мы запрашиваем данные из другой таблицы. Мы не обращаемся ни к таблице “books”, ни к таблице “borrowings”. Вместо этого мы обращаемся к новой таблице, которая создалась соединением этих двух таблиц.
— это, считай, новая таблица, которая была сформирована комбинированием всех записей из таблиц «books» и «borrowings», в которых значения совпадают. Результатом такого слияния будет:
А потом мы делаем запрос к этой таблице так же, как в примере выше. Это значит, что при соединении таблиц нужно заботиться только о том, как провести это соединение. А потом запрос становится таким же понятным, как в случае с «простым запросом» из пункта 3.
Давайте попробуем чуть более сложное соединение с двумя таблицами.
Теперь мы хотим получить имена и фамилии людей, которые взяли из библиотеки книги автора “Dan Brown”.
На этот раз давайте пойдем снизу вверх:
Шаг Step 1 — откуда берем данные? Чтобы получить нужный нам результат, нужно соединить таблицы “member” и “books” с таблицей “borrowings”. Секция JOIN будет выглядеть так:
Шаг 2 — какие данные показываем? Нас интересуют только те данные, где автор книги — “Dan Brown”
Шаг 3 — как показываем данные? Теперь, когда данные получены, нужно просто вывести имя и фамилию тех, кто взял книги:
Супер! Осталось лишь объединить три составные части и сделать нужный нам запрос:
Что даст нам:
| First Name | Last Name |
|---|---|
| Mike | Willis |
| Ellen | Horton |
| Ellen | Horton |
Отлично! Но имена повторяются (они не уникальны). Мы скоро это исправим.
5. Агрегирование
Грубо говоря, агрегирования нужны для конвертации нескольких строк в одну. При этом, во время агрегирования для разных колонок используется разная логика.
Давайте продолжим наш пример, в котором появляются повторяющиеся имена. Видно, что Ellen Horton взяла больше одной книги, но это не самый лучший способ показать эту информацию. Можно сделать другой запрос:
Что даст нам нужный результат:
| First Name | Last Name | Number of books borrowed |
|---|---|---|
| Mike | Willis | 1 |
| Ellen | Horton | 2 |
Почти все агрегации идут вместе с выражением . Эта штука превращает таблицу, которую можно было бы получить запросом, в группы таблиц. Каждая группа соответствует уникальному значению (или группе значений) колонки, которую мы указали в . В нашем примере мы конвертируем результат из прошлого упражнения в группу строк. Мы также проводим агрегирование с , которая конвертирует несколько строк в целое значение (в нашем случае это количество строк). Потом это значение приписывается каждой группе.
Каждая строка в результате представляет собой результат агрегирования каждой группы.
Можно прийти к логическому выводу, что все поля в результате должны быть или указаны в , или по ним должно производиться агрегирование. Потому что все другие поля могут отличаться друг от друга в разных строках, и если выбирать их ‘ом, то непонятно, какие из возможных значений нужно брать.
В примере выше функция обрабатывала все строки (так как мы считали количество строк). Другие функции вроде или обрабатывают только указанные строки. Например, если мы хотим узнать количество книг, написанных каждым автором, то нужен такой запрос:
Результат:
| author | sum |
|---|---|
| Robin Sharma | 4 |
| Dan Brown | 6 |
| John Green | 3 |
| Amish Tripathi | 2 |
Здесь функция обрабатывает только колонку и считает сумму всех значений в каждой группе.
6. Подзапросы
Подзапросы это обычные SQL-запросы, встроенные в более крупные запросы. Они делятся на три вида по типу возвращаемого результата.
Запрос для удаления данных (delete)
SQL-запрос для удаления данных строится следующим образом:
delete from table where clause;
где delete from — это начало запроса, table — это конкретное название таблицы, where — указывает, что далее будут указаны фильтры строк, которые необходимо удалить, clause — это сами фильтры для выборки строк. После sql-запроса ставится точка с запятой.
Важно отметить, что фильтр может быть весьма сложным и состоять из большого количества условий. Для его составления используются три операнда — and (И), or (ИЛИ) и скобки (для отделения сложных выражений)
Логика здесь аналогична самой простой математики.
Примечание: Важно отметить, что часть where с clause являются необязательными. То есть, если фильтр не требуется, то их можно не писать
Однако, если фильтр нужен, то обе составляющих необходимо использовать в запросе.
К примеру, представим, что вам необходимо удалить все строки, где возраст больше 1 и меньше 5, или же строки, в которых указывается имя Масяня. Тогда запрос выглядел бы так:
delete from somedata where (Age > 1 and Age < 5) or Name = 'Масяня';
Если разбирать логику, то этот запрос говорит базе данных, чтобы она проверила каждую строчку таблицы somedate и если строка удовлетворяет условиям, то ее необходимо удалить.
Запрос вставки (insert)
Запрос вставки строится следующим образом:
insert into table (col1, col2, ..., colN) values (val11, val12, ..., val1N), (val21, val22, ..., val2N), ..., (valM1, valM2, ..., valMN);
где insert into — это начало запроса, table — это конкретное название таблицы, (col1, col2, …, colN) — это названия колонок в нужном порядке (сделано для удобства), values — указывает, что далее будут указаны строки для вставки, (val11, val12, …, val1N), (val21, val22, …, val2N), …, (valM1, valM2, …, valMN) — это конкретные значения для вставки (в соответствующем порядке с колонками)
Важно, что после каждого sql-запроса необходимо ставить точку с запятой. Это позволяет отделять одни запросы от других
К примеру, если бы потребовалось добавить две строки в таблицу из примера somedate, то sql-запрос выглядел бы так:
insert into somedata (Name, Age, Date) values ('Коля', 10, '04.05.2009'), ('Анастасия', 22, '12.02.1997');
Это строчки появились бы в конце таблицы. Конечно, в реальных базах данных, размещение строчек может сильно зависеть от применяемых механизмов, однако по умолчанию это так.
Тинькофф Инвестиции от Тинькофф Брокер. Достоинства
Выражение CASE – условный оператор языка SQL
| Первая форма: | Вторая форма: |
|---|---|
| CASE WHEN условие_1 THEN возвращаемое_значение_1 … WHEN условие_N THEN возвращаемое_значение_N END |
CASE проверяемое_значение WHEN сравниваемое_значение_1 THEN возвращаемое_значение_1 … WHEN сравниваемое_значение_N THEN возвращаемое_значение_N END |
Разберем на примере первую форму CASE:
| ID | Name | Salary | SalaryTypeWithELSE | SalaryTypeWithoutELSE |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 5000 | ЗП >= 3000 | ЗП >= 3000 |
| 1001 | Петров П.П. | 1500 | ЗП < 2000 | NULL |
| 1002 | Сидоров С.С. | 2500 | 2000 <= ЗП < 3000 | 2000 <= ЗП < 3000 |
| 1003 | Андреев А.А. | 2000 | 2000 <= ЗП < 3000 | 2000 <= ЗП < 3000 |
| 1004 | Николаев Н.Н. | 1500 | ЗП < 2000 | NULL |
| 1005 | Александров А.А. | 2000 | 2000 <= ЗП < 3000 | 2000 <= ЗП < 3000 |
Разберем на примере вторую форму CASE:
- Сотрудникам ИТ-отдела выдать по 15% от ЗП;
- Сотрудникам Бухгалтерии по 10% от ЗП;
- Всем остальным по 5% от ЗП.
| ID | Name | Salary | DepartmentID | NewYearBonusPercent | BonusAmount |
|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 5000 | 1 | 5% | 250 |
| 1001 | Петров П.П. | 1500 | 3 | 15% | 225 |
| 1002 | Сидоров С.С. | 2500 | 2 | 10% | 250 |
| 1003 | Андреев А.А. | 2000 | 3 | 15% | 300 |
| 1004 | Николаев Н.Н. | 1500 | 3 | 15% | 225 |
| 1005 | Александров А.А. | 2000 | NULL | 5% | 100 |
- Первым делом ЗП должны получить сотрудники у кого оклад меньше 2500
- Те сотрудники у кого оклад больше или равен 2500, получают ЗП во вторую очередь
- Внутри этих двух групп нужно упорядочить строки по ФИО (поле Name)
| ID | Name | Salary |
|---|---|---|
| 1005 | Александров А.А. | 2000 |
| 1003 | Андреев А.А. | 2000 |
| 1004 | Николаев Н.Н. | 1500 |
| 1001 | Петров П.П. | 1500 |
| 1000 | Иванов И.И. | 5000 |
| 1002 | Сидоров С.С. | 2500 |
| ID | Name | Salary | DepartmentID | NewYearBonusPercent1 | NewYearBonusPercent2 |
|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 5000 | 1 | 5% | 5% |
| 1001 | Петров П.П. | 1500 | 3 | 15% | 15% |
| 1002 | Сидоров С.С. | 2500 | 2 | 10% | 10% |
| 1003 | Андреев А.А. | 2000 | 3 | 15% | 15% |
| 1004 | Николаев Н.Н. | 1500 | 3 | 15% | 15% |
| 1005 | Александров А.А. | 2000 | NULL | — | 5% |
Инструкция SHOW
Как узнать содержимое той или иной базы данных? Или содержимое конкретной таблицы? Для этого используется инструкция .
Этот полезный инструмент позволяет отслеживать содержимое баз данных, показывать структуру их таблиц.
SHOW DATABASES
Например, команда выводит список баз данных, которые находятся под управлением конкретного сервера.
На протяжении всего курса статей мы будем использовать движок MySQL и работать с обычным терминалом Linux для выполнения SQL запросов.
Самый простой способ создания сервера MySQL — установить бесплатные инструменты, такие как XAMPP или WAMP, которые включают в себя все необходимые утилиты. Но так же можно установить всё вручную.
SHOW TABLES
Для того, чтобы посмотреть все доступные таблицы в выбранной базе данных, используется команда . Она нужна для отображения всех таблиц в текущей выбранной базе данных MySQL.
SHOW COLUMNS
отображает информацию о столбцах в данной таблице.
В следующем примере показаны столбцы в таблице wp_comments:
отображает следующие значения для каждого столбца таблицы:
- Field: имя столбца
- Type: тип данных столбца
- Key: указывает, индексирован ли столбец
- Default: значение по умолчанию для столбца
- Extra: может содержать любую дополнительную информацию о данном столбце
Столбцы для таблицы wp_comments были автоматически созданы WordPress, как и вся база данных моего сайта.
Выборка информации
Для извлечения значений из БД используется команда SELECT. Пишем такой код:
SELECT * FROM ‘table’ WHERE id = ‘1’
В данном примере в таблице выбираем все имеющиеся поля. Это происходит если прописать в команде звездочку «*». Если нужно выбрать какое-то выборочное значение пишем так:
SELECT log , pass FROM table WHERE id = ‘1’
Необходимо отметить, что умения работать с базами данных будет недостаточно. Для создания профессионального интернет-проекта придется научиться добавлять на страницы данные из БД. Для этого ознакомьтесь с языком веб-программирования php. В этом вам поможет классный курс Михаила Русакова.

Типы данных и выражения sql
Типы
данных
Символьный
тип данных содержащий буквы, цифры,
специальные символы
CHAR
или CHAR
(n)
– символьные строки фиксированные
данные
VARCHAR
(n)
– символьные строки
Целые
числа
INTЕGER
или INT
– целое для решения которого отводится,
как байта
SMALLINT
– короткое
целое (2 байта)
FLOAT
–
число плавающих точек
DECIMAL
(p)
– аналогично FLOAT
с числовым значение цифр р
DECIMAL
(p,
n)
– аналогично предыдущим, р – общее
количество десятичных чисел
Денежный
тип
MONEY
(p,
n)
– аналогично типу DECIMAL
(p,
n)
Дата
и время
DATE
— дата
TIME
— время
INTERVAL
– временный интервал
DATETIME
– момент время
Двоичные
данные
BINARY
BYTE
BLOB
– хранить данные любого объема в двоичном
коде
Последовательный
тип
SERIAL
– тип данных на основе INTEGER
позволяющий сформировать уникальные
значения
Выражения
Арифметические
выражения
+,
-, *, %, /, ^,
Логические
операции
AND
– логическое умножение
OR
– лог сложение
NOT
–лог отриц
Текстовые
операции
&
— слияние слов
Пример
выражения
Kol*Price
(Kol*Price)/8200
AVG
Язык
SQL
оперирует терминами: таблица, строка,
столбец или колонка.
Полное
имя таблицы: имя _ владельца.имя_таблицы
Полное
имя столбца: имя _ владельца.имя_столбца
Основной
яз SQL составляет операции, условно
разбитые на несколько групп.
Категории
операторов
SQL:
-
Date
Definition Language (DDC) -
Date
Manipulation Language (DML) -
Date
Control Language (DCL) -
Transaction
Control Language (TCL) -
Cursor
Control Language (CCL)
Команда SPOOL
Команда позволяет сохранять вывод одного и более SQL-операторов в файлах операционной системы, как в UNIX, так и в Windows:
SQL> SET LINESIZE 180 SQL> SPOOL employee.lst SQL> SELECT emp_id, last_name, salary, manager FROM employee; SQL> SPOOL OFF;
По умолчанию создаваемые этой командой буферные (spooled) текстовые файлы сохраняются как . Хотя по умолчанию принято сохранять вывод в файле,его также можно отправлять и на принтер. Буферизация файлов является очень полезным приемом при использовании SQL для оказания помощи в написании SQL-сценариев, и некоторые примеры его применения можно найти в приложении.
С помощью команды можно добавлять данные в существующий буферный файл, а также полностью заменять его (по умолчанию происходит замена). Ниже приведен весь синтаксис этой команды:
SPOOL { имя_файла |REP|APP]| OFF | OUT }
Ниже описаны параметры команды .
- . Специфицирует имя буферного файла. Расширение может выглядеть по-разному, но в большинстве случаев используется предлагаемое по умолчанию расширение .lst.
- . Указывает, что требуется создать новый файл.
- . Указывает на необходимость замены содержимого существующего файла или создания нового файла, если он не существует. Это поведение по умолчанию.
- . Указывает на необходимость добавить содержимое буфера в конец указанного файла.
- . Указывает, что требуется остановить процесс буферизации.
- : Указывает, что требуется остановить процесс буферизации и отправить файл на принтер по умолчанию. В некоторых операционных системах этот параметр не поддерживается.
У команды имеет множество способов применения. Например, она легко экспортируется для перехвата результатов оператора . Перед этим, однако, должен обязательно задаваться формат вывода путем определения значений для переменных и . Ниже приведен пример:
SQL> SPOOL /u01/app/oracle/data/employees.txt; SQL> SELECT * FROM hr.employees; SQL> SPOOL OFF;
В этом примере файл служит для перехвата всех данных из таблицы . Далее его можно будет использовать для загрузки данных в другую таблицу с помощью утилиты SQL*Loader.
Оператор join: объединение записей из двух таблиц
В нашей таблице для хранения погодного дневника город сохраняется как идентификатор, поэтому при обычном чтении данных из этой таблицы вместо названия города стоит непонятное число. Чтобы подставить на место числа действительное значение, а конкретнее — название города, в SQL существуют операторы объединения — .
Поддержка операторов объединения и позволяет базе данных называться реляционной.
Поменяем запрос на показ погодных записей, чтобы он объединял две таблицы, а в поле города показывалось его название, а не идентификатор:
Важно усвоить три самых главных момента:
- При чтении из объединённых таблиц, в перечислении полей после SELECT нужно явно указывать в поле имени также имя таблицы, с которой производится объединение.
- Всегда есть основная таблица (тб1), из которой читается большинство полей и присоединяемая (тб2), имя которой определяется после оператора JOIN.
- Помимо указания имени второй таблицы, обязательно следует указать условие, по которому будет происходить объединение. В этом примере таким условием будет соответствие идентификатора города из тб1 (weather_log.city_id) первичному ключу города из тб2 (cities.id).
Команды ACCEPT и PROMPT
Команда применяется для считывания вводимых пользователем данных с экрана и сохранения их в какой-то переменной. Эту переменную можно либо указать самостоятельно, либо позволить создавать ее SQL*Plus. Обычно команда применяется для считывания данных, вводимых пользователем в ответ на приглашения в интерфейсе SQL*Plus.
Что касается команды , то она полезна при создании интерактивных сценариев. Она умеет отправлять от SQL*Plus на экран сообщение или просто пустую строку,и обычно применяется для получения входных данных от пользователя или вывода комментариев. Например, включение в сценарий строки «» приведет к получению следующего вывода:
SQL> "Тестирование"
Команды и в SQL-сценарии обычно используются вместе и служат,как правило, для запроса у пользователя входных данных и сохранения этих данных в переменных для дальнейшей работы с ними в программе. Ниже приведен пример, иллюстрирующий использование этих команд:
SQL> PROMPT 'Пожалуйста, введите свою фамилию' SQL> ACCEPT lastname CHAR FORMAT a20 alapati
Что такое язык SQL и оператор SELECT
SQL – это язык запросов, который служит для манипуляции (управления) данными в реляционных базах данных. Имеет широкую популярность и поэтому любой уважающий себя IT-к должен знать основы этого языка, так как базы данных есть практически в каждой компании.
SELECT – оператор языка SQL, относится к группе операторов манипуляции данными (Data Manipulation Language, DML) и служит для выборки данных из базы данных.
Примечание! Для того чтобы изучать язык SQL и базы данных существуют специальные бесплатные редакции крупных СУБД, например в SQL Server от компании Microsoft есть редакция Express. Как установить данную СУБД можете почитать в материале — Описание установки Microsoft SQL Server 2016 Express.
Вот самый простой пример использования оператора SELECT.
SELECT * FROM Table
где,
- * — показать все данные;
- FROM — из источника;
- Table — название источника (в нашем случае таблица).
Но, на практике, зачастую нам нужны не все данные из таблицы, а иногда только некоторые колонки, для этого просто указываем вместо * название нужной колонки (или колонок), например:
SELECT Price FROM Table
где, Price и есть название колонки.
Примечание! В качестве примера мы используем простую таблицу с перечислением моделей компьютеров, их ценой и названием.
Если Вам нужно указать несколько колонок, то просто перечисляйте их через запятую после оператора SELECT, например
SELECT price, name, model FROM Table
где, price, name, model это колонки из таблицы Table.
Оператор update: обновление информации в БД
При добавлении записи очень легко совершить ошибку: сделать опечатку, не указать значение для одного из полей, и так далее.
Естественно, язык SQL предлагает возможности для редактирования уже созданных записей.
Предположим, что при добавлении погодной записи пользователь ошибся и ввёл неверную дату. Чтобы исправить эту ошибку, нужно использовать оператор обновления — .
Запрос с этим оператором позволяет обновить значение одного или нескольких полей в существующей записи. Выглядит он так:
Но чтобы правильно составить запрос, необходимо определить условие для поиска записи, которую предлагается обновить. В противном случае, если не указать это условие, то будут обновлены абсолютно все записи в таблице.
В качестве такого условия лучше всего использовать первичный идентификатор записи. Поэтому, прежде чем выполнять запрос обновления, нужно выполнить запрос на чтение информации из таблицы, чтобы узнать, под каким идентификатором сохранилась ошибочная запись.
Допустим, этот идентификатор — единица, а правильная дата — пятое сентября 2017 года.
Запрос на обновление:
Что это такое
Sql — язык структурированных запросов. Создан для определения типа данных, предоставления доступа к ним и обработке информации за короткие промежутки времени. Он описывает компоненты или какие-то результаты, которые вы хотите видеть на интернет-проекте.
Если говорить по-простому, то этот язык программирования позволяет добавлять, изменять, искать и отображать информацию в БД. Популярность mysql связана с тем, что он используется для создания динамических интернет-проектов, основа которых составляет база данных. Поэтому для разработки функционального блога вам необходимо выучить этот язык.

Общая характеристика языка запросов SQL
SQL может выполнять операции над таблицами и над данными таблиц.
Язык SQL называют встроенным, т.к. он содержит функций полноценного языка разработки, а ориентируется на доступ к данным, вследствие чего он входит в состав средств разработки приложений. Стандарты языка SQL поддерживают языки программирования Pascal, Fortran, COBOL, С и др.
Существует 2 метода использования встроенного SQL:
- статическое использование языка (статический SQL) – в тексте программы содержатся вызовы функций SQL, которые включают в исполняемый модуль после компиляции.
- динамическое использование языка (динамический SQL) – динамическое построение вызовов функций SQL и их интерпретация. Например, можно обратиться к данным удаленной БД в процессе выполнения программы.
Язык SQL (как и другие языки для работы с БД) предназначен для подготовки и выполнения запросов. В результате выполнения запроса данных из одной или нескольких таблиц получают множество записей, которое называют представлением.
Определение 1
Представление – это таблица, которая формируется в результате выполнения запроса.